k8s - network
0. INDEX
- Prerequisite - switching, Routing
- Prerequisite - DNS
- Prerequisite - CoreDNS
- Prerequisite - Network Namespaces
- Prerequisite - Docker Networking
- Prerequisite - CNI
- Cluster Networking
- Pod Networking
- CNI in kubernetes
- CNI weave
- IP Address Management - Weave
- Service Networking
- DNS in kubernetes
1. Prerequisite - switching, Routing

-시스템 a와 b를 switch에 연결할 수 있고, switch는 두 시스템을 포함한 network를 만들게 된다.
-시스템 a, b에서 switch에 연결하기 위해서는 각 호스트의 interface가 필요하다.
[통신 셋업 과정]
1.이더넷 케이블을 사용해서 호스트 a,b의 NIC와 switch의 포트를 물리적으로 연결한다.
2.ip addr add 명령어로 스위치로 연결된 네트워크 내에서 해당 호스트 장치 내 특정 인터페이스에 대해 ip를 지정한다.
3.ping 명령어로 시스템 a, b 간 통신을 확인한다.
*그럼 다른 네트워크 간 통신은 어떻게 가능할까? -> 라우터로 가능하다.

-라우터는 하나의 서버로 생각할 수 있다.
-라우터가 각 네트워크(스위치)에 연결되기 때문에 총 두개로, 각 네트워크에서 고유 ip를 가진다.
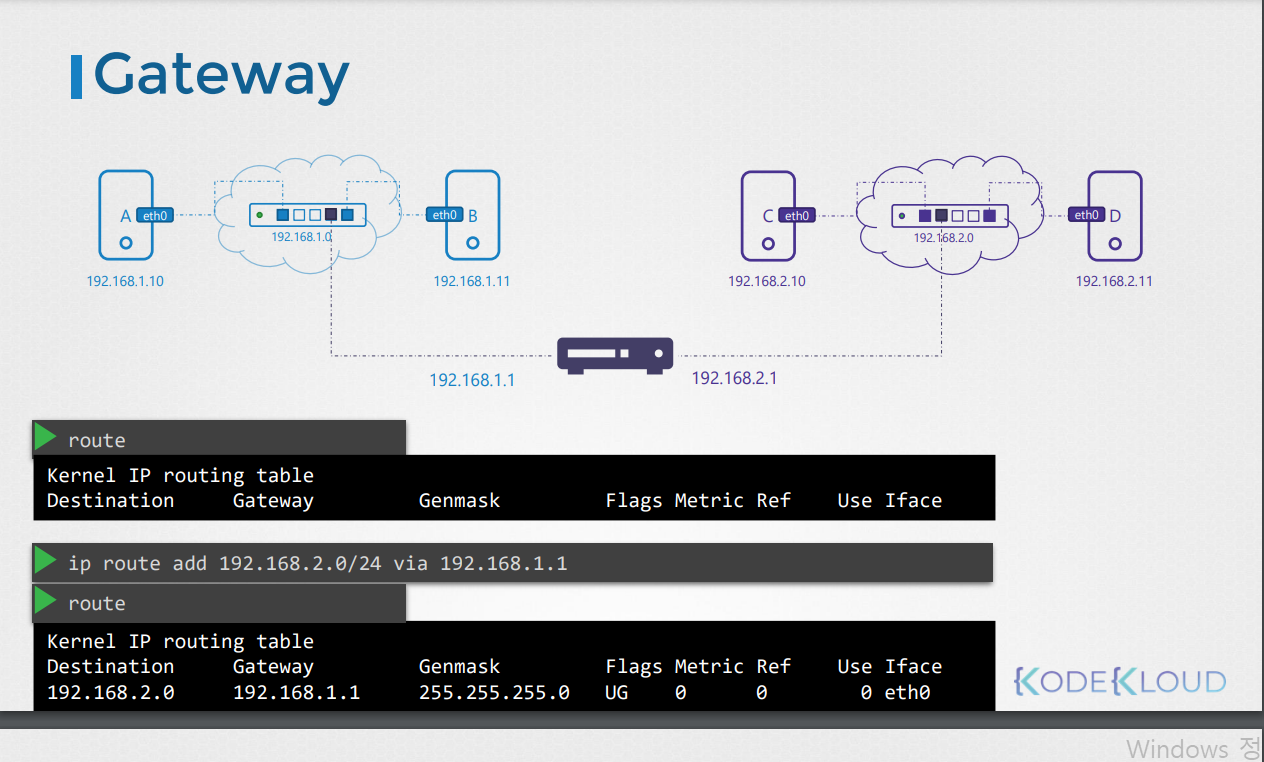
-호스트 b에서 다른 네트워크로 통신하기 위해서는 ip route add 명령어로, 다른 네트워크로 통하는 문인 게이트웨이를 지정해줘야 한다.
-각각의 호스트마다 위 명령어를 지정해줘야 해당 호스트에서 다른 네트워크로의 통신이 가능하다.
*그럼 다른 네트워크 중 인터넷으로 통신하려면 어떻게 해야 할까?

-ip route add default(or 0.0.0.0) 명령어로 모든 네트워크로 라우팅되도록 설정할 수 있다. 즉 하나의 라우터에 목적지 네트워크를 여러 개 설정 가능함
*그럼 라우터도 서버이니, 리눅스 호스트를 라우터로서 어떻게 셋업할 수 있을까?

-호스트 a에서 c로 트래픽이 이동되려면 b를 라우터로 설정해서 도달할 수 있다. 마찬가지로 c에서도 b를 라우터로 설정해야 한다.
-설정 후에 ping을 하더라도 unreachable은 사라지지만 응답은 여전히 오지 않는다. 그 이유는, 리눅스에서는 호스트 b에서 하나의 eth1로 들어온 패킷이 다른 eth0을 통해서 밖으로 나갈 수 없기 때문이다. 보안 상 이유로 그렇다.
*그럼 호스트 b를 매개로 통신되도록 하려면?

-/proc/sys/net/ipv4/ip_forward 내 forword 설정을 1로 바꾸거나, 영구적으로 바꾸기 위해서는 /etc/sysctl.conf 내 config를 바꾸면 된다.
[요약]

-위 명령어들은 재부팅 전까지만 유효하다. 영구적 변경을 위해서는 /etc/network/interface 내 설정을 수정하면 된다.
2. Prerequisite - DNS

-host a는 b를 /etc/hosts 내 설정된 hostname으로 통신할 수 있지만, 이건 호스트b의 실제 hostname을 보장하지는 않는다. 하나의 ip에 hostname을 동시 설정할 수 있다.
-이렇게 /etc/hosts 파일을 통해 번역을 하는 과정을 name resolution이라고 한다.
*여러 호스트에서 관리되는 매핑 정보가 많아지고 그 중 호스트 ip가 변경되는 경우 수정에 어려움이 있다. 어떻게 해결되었을까?
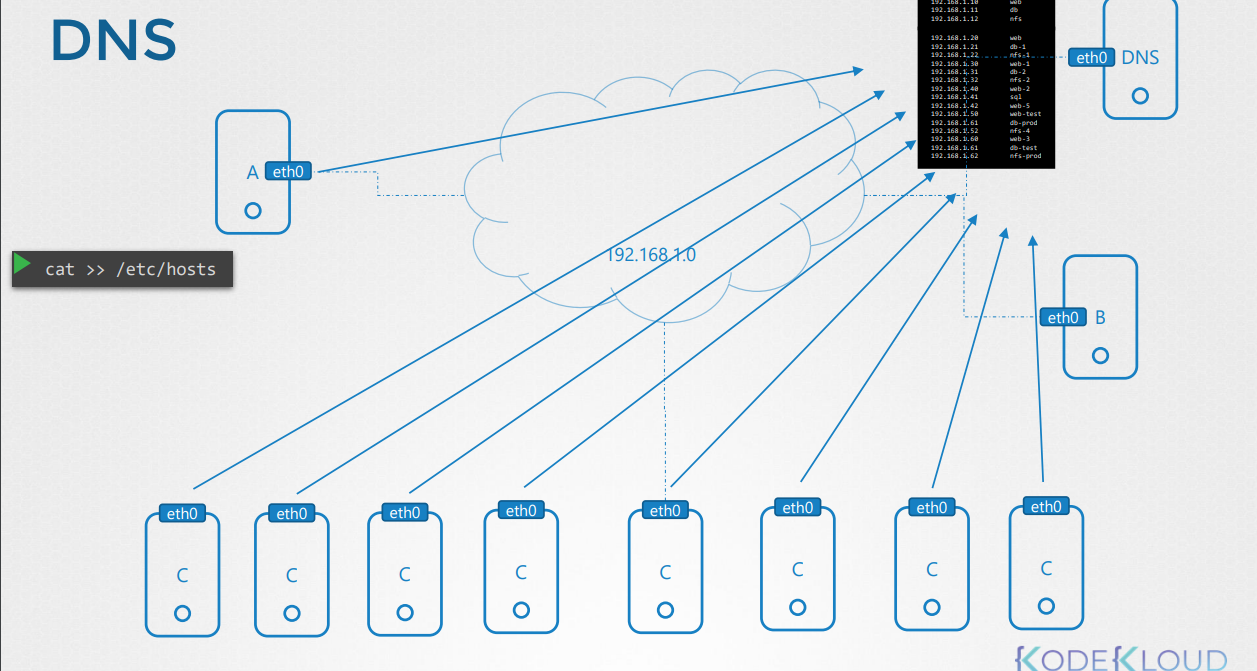
-각 호스트에서 관리되던 매핑정보를 하나의 dns 서버에서 관리하게 되었다.

-/etc/resolv.conf 파일 내 nameserver를 호스트네임으로 지정해서 dns 서버를 바라보게 하면된다.
*내가 임의로 지정한 test라는 호스트네임이 dns 서버, /etc/hosts에 모두 존재한다면?

-기본값은, /etc/hosts -> dns 서버 순으로 찾아진 ip에 먼저 접근한다.
-/etc/nsswitch.conf에서 위 순서를 수정할 수 있다.
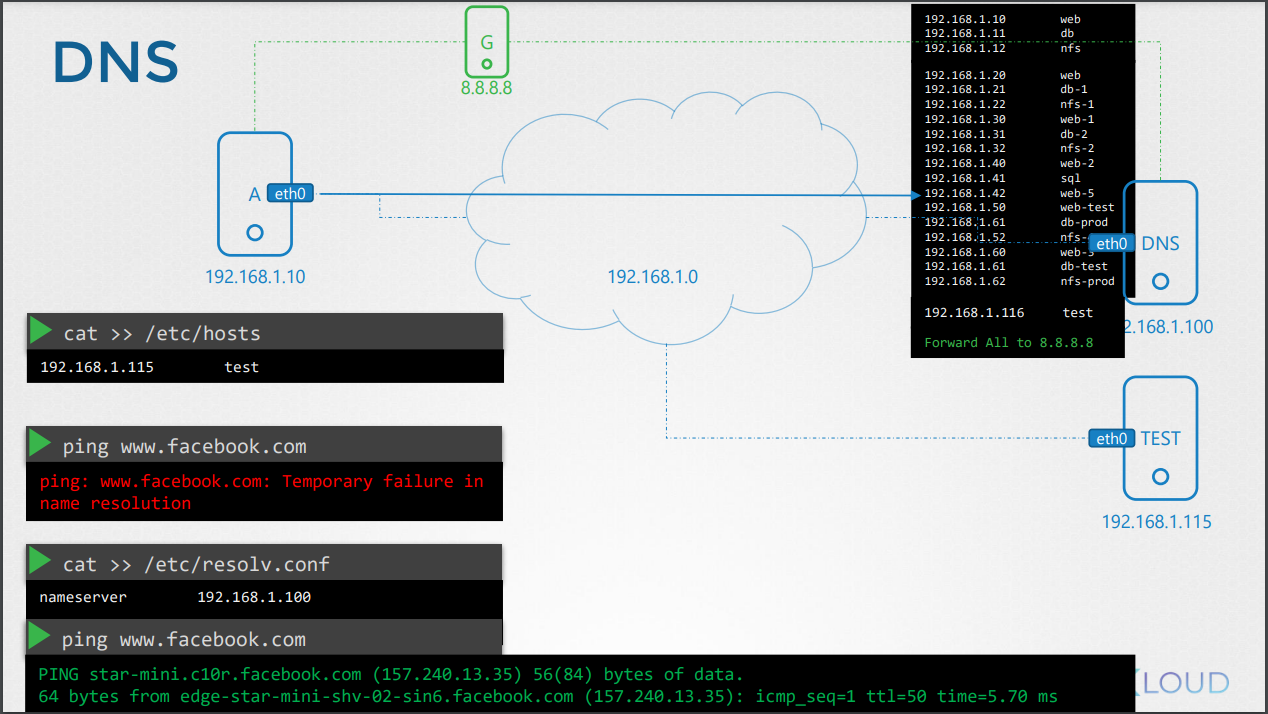
-호스트네임을 찾지 못하면 당연히 접속불가.
-name server를 다중으로 설정할 수 있다.
*도메인 네임이란?

-계층적으로 dns 서버가 나뉘어져 있다.
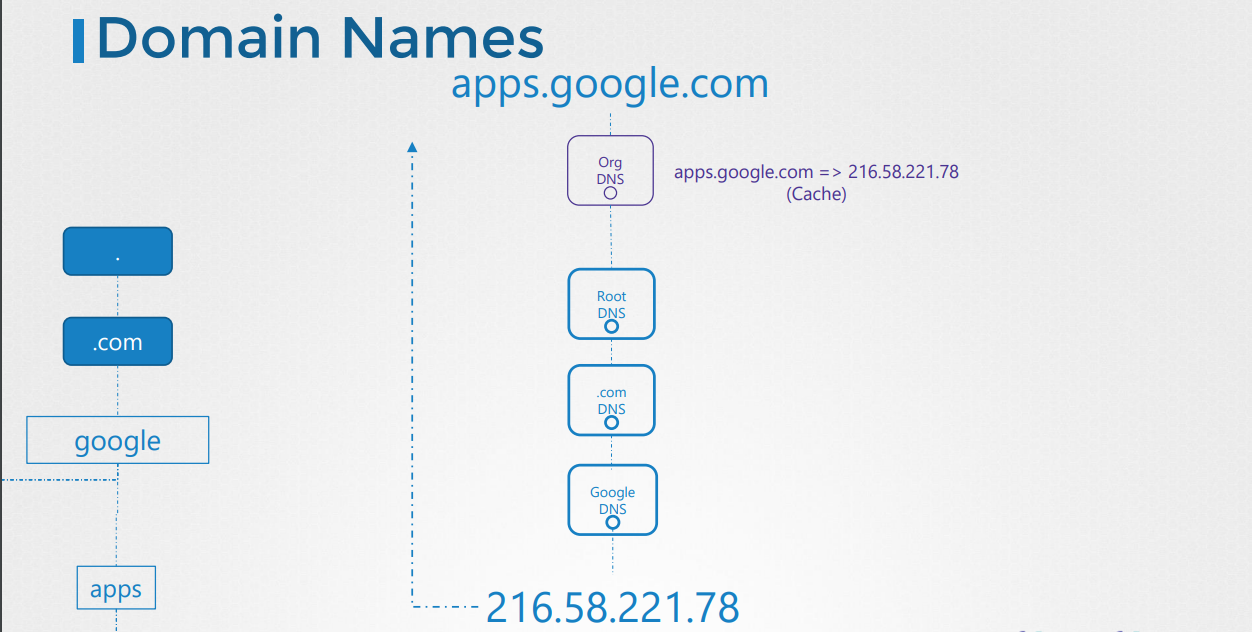
-로컬 dns 서버에서 모르면, 최상위 dns 서버부터 계층적으로 접근하여 최종 ip를 구하고 이 ip-호스트네임 정보를 로컬 dns에
캐시한다.
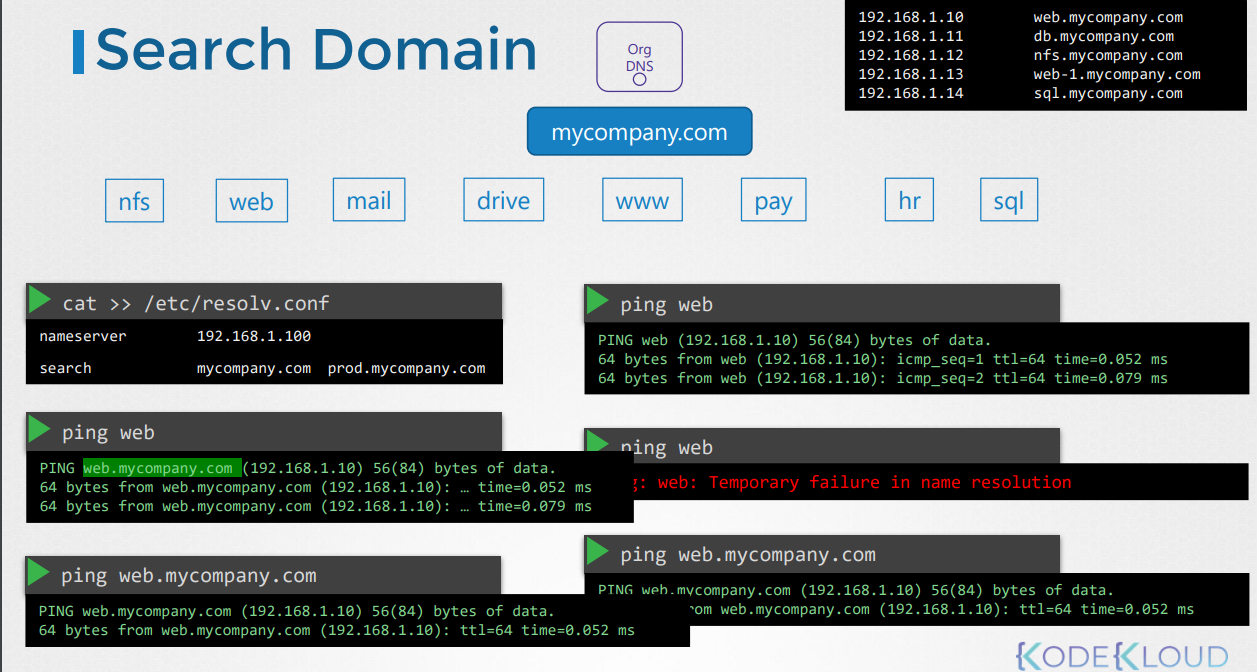
-로컬 dns는 /etc/resolv.conf에 설정함.
-search 설정으로, 상위 도메인이름이 자동으로 검색되도록 할 수 있음. 다중 설정도 가능.
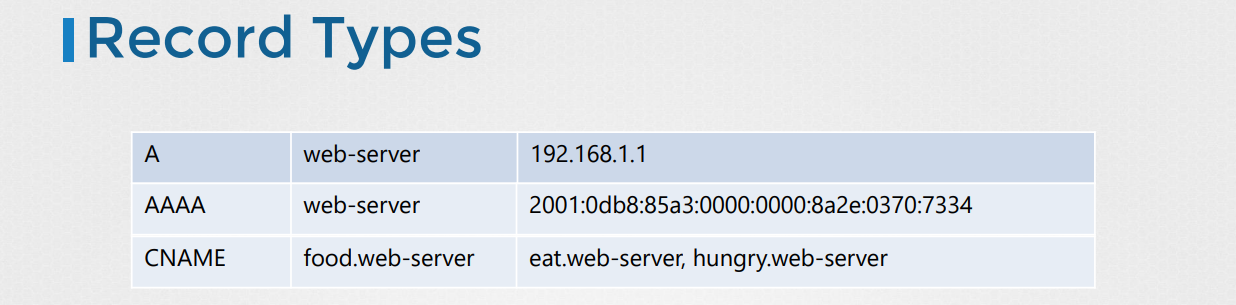

-nslookup 명령어로, hostname에 대한 ip 정보를 얻을 수 있다.
-/etc/hosts 파일은 참조하지 않으며, dns server에서 정의된 정보만 확인 가능하다.
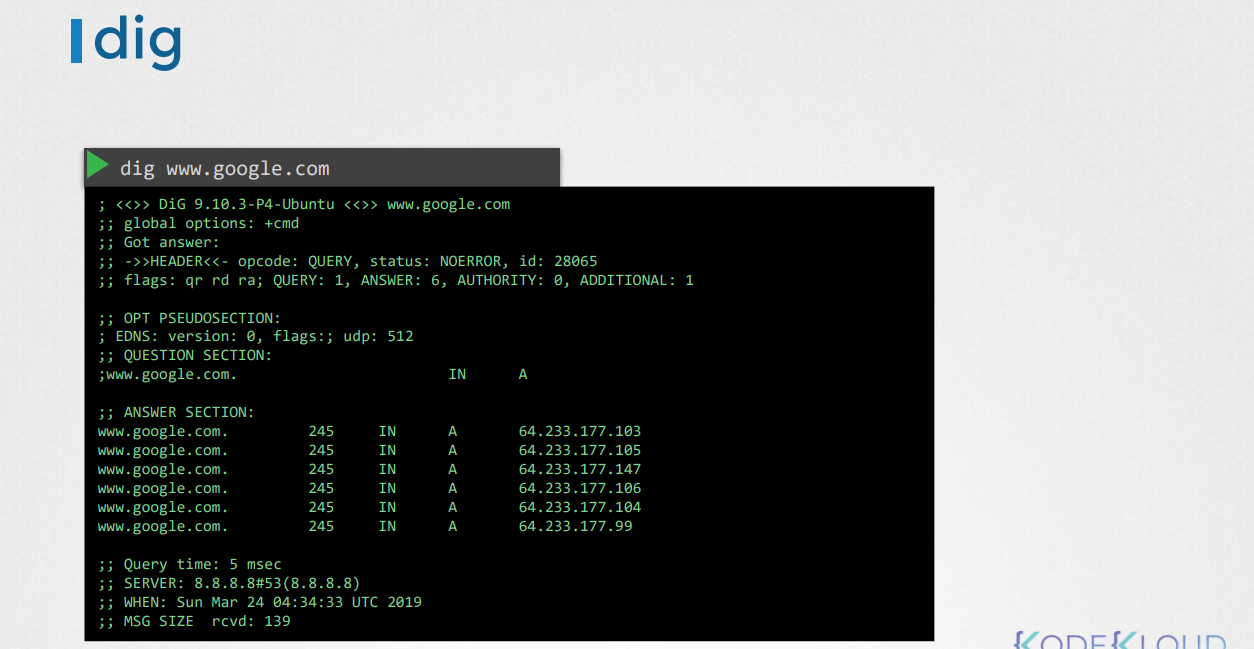
-dig 명령어로, 디테일하게 확인 가능.
3. Prerequisite - CoreDNS
[호스트를 dns 서버로 구성하는 방법]
-coreDNS는 바이너리 다운로드, 도커 이미지로 가져올 수 있다.
[CoreDNS 구성 순서]
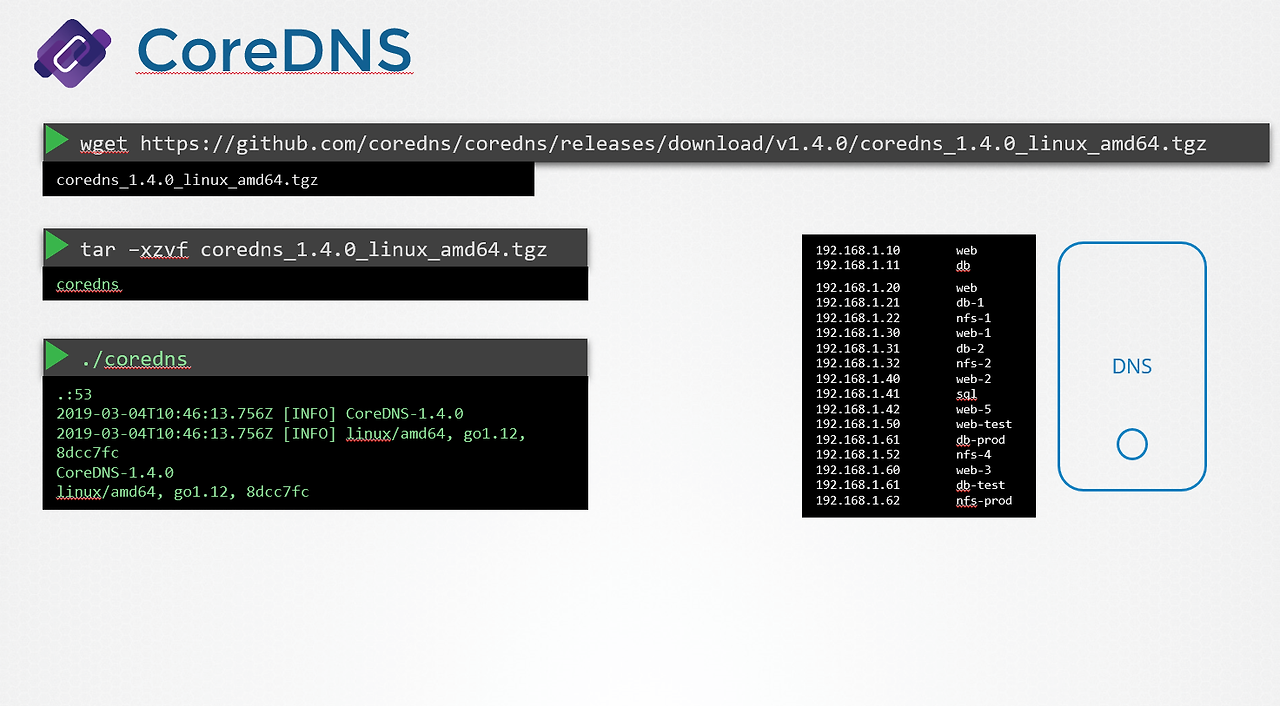
1.CoreDNS 바이너리 파일 실행 시 위와 같이 53포트로 실행됨.

2./etc/hosts 파일 내 name solution 대상인 매핑 정보를 설정한다.
3.CoreDNS의 구성파일인 Corefile에서, 위처럼 /etc/hosts 경로에서 매핑정보를 가져올 수 있도록 구성.
4. 위 방식 말고, k8s에서 plugin 사용을 통해 매핑정보를 구성하는 방식도 있다.
4. Prerequisite - Network Namespaces
-네트워크 네임스페이스는 리눅스에서 네트워크 격리를 구현하기 위한 환경이다.
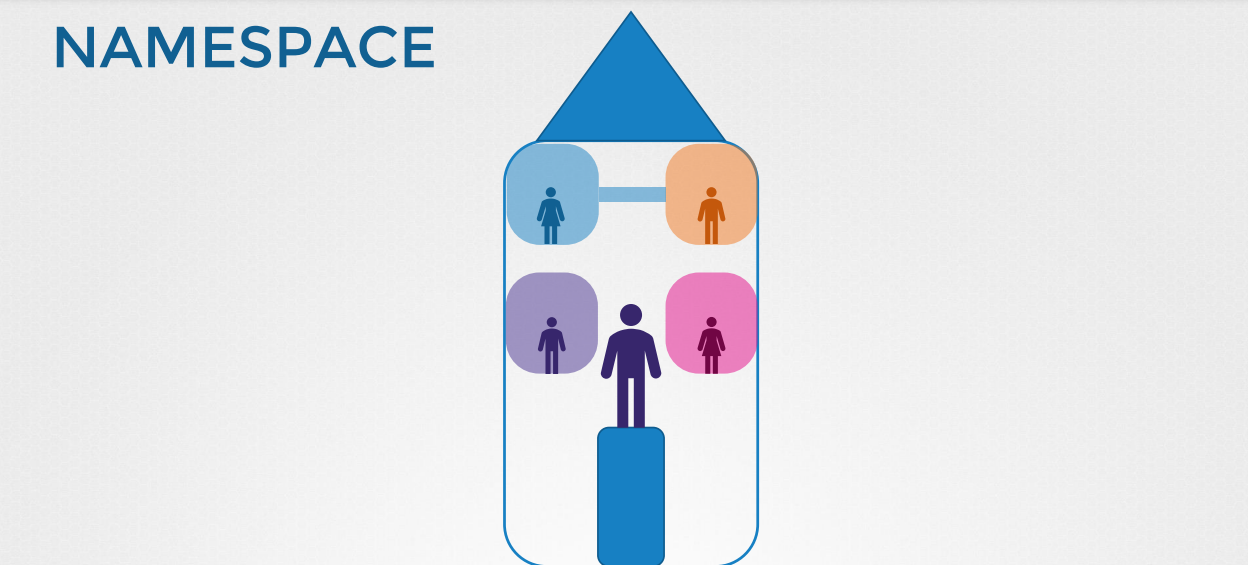
-호스트가 집이면, 네임스페이스는 방처럼 격리된 환경을 말한다.
-호스트는 각 컨테이너를 들여다 볼 수 있으며, 컨테이너 간 연결을 구성할 수도 있다.

-host와 container 상에서 특정 프로세스는 다른 PID로 확인된다.
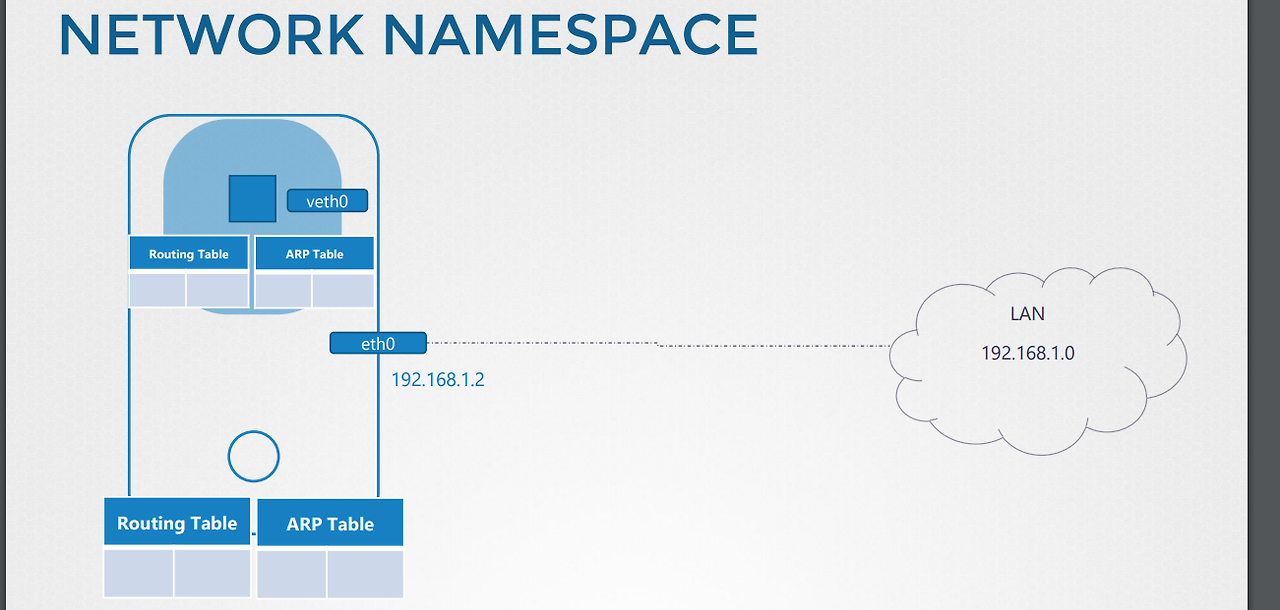
-네트워크 네임스페이스는 내부 네트워크 정보를 외부에 노출시키지 않는다.
-네임스페이스 내부에 존재하는 컨테이너는 자체 인터페이스, ARP, Route 테이블을 가진다.

-ip netns add 명령어로 네트워크 네임스페이스 추가 가능.
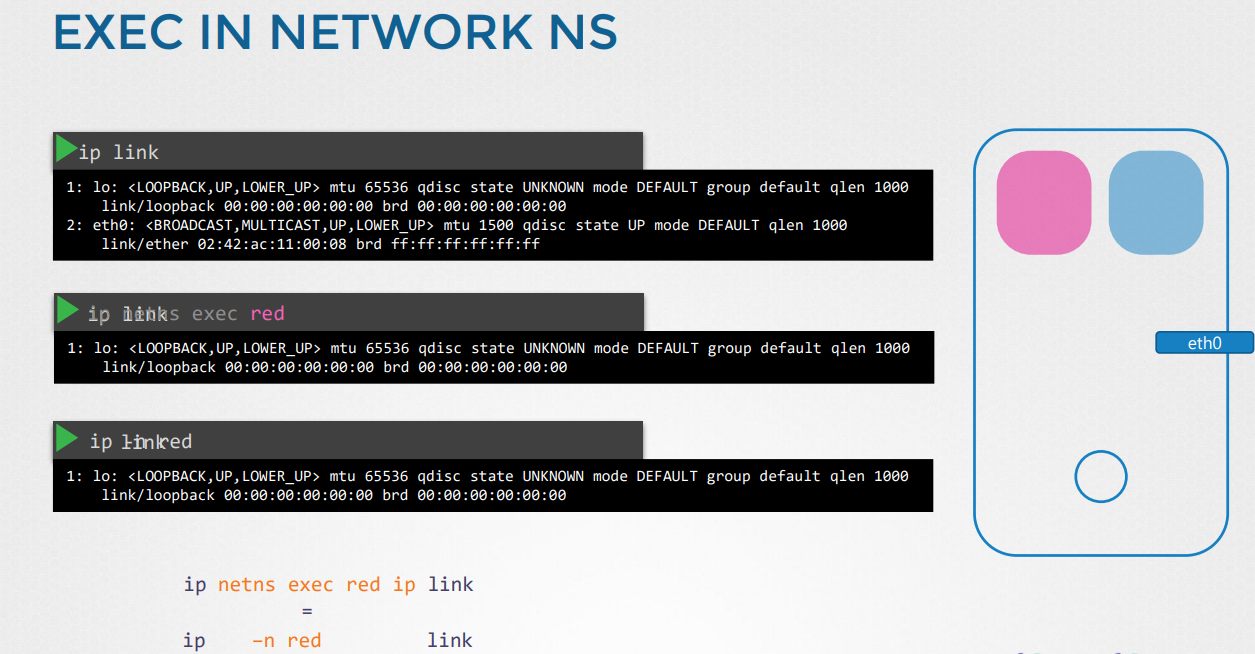
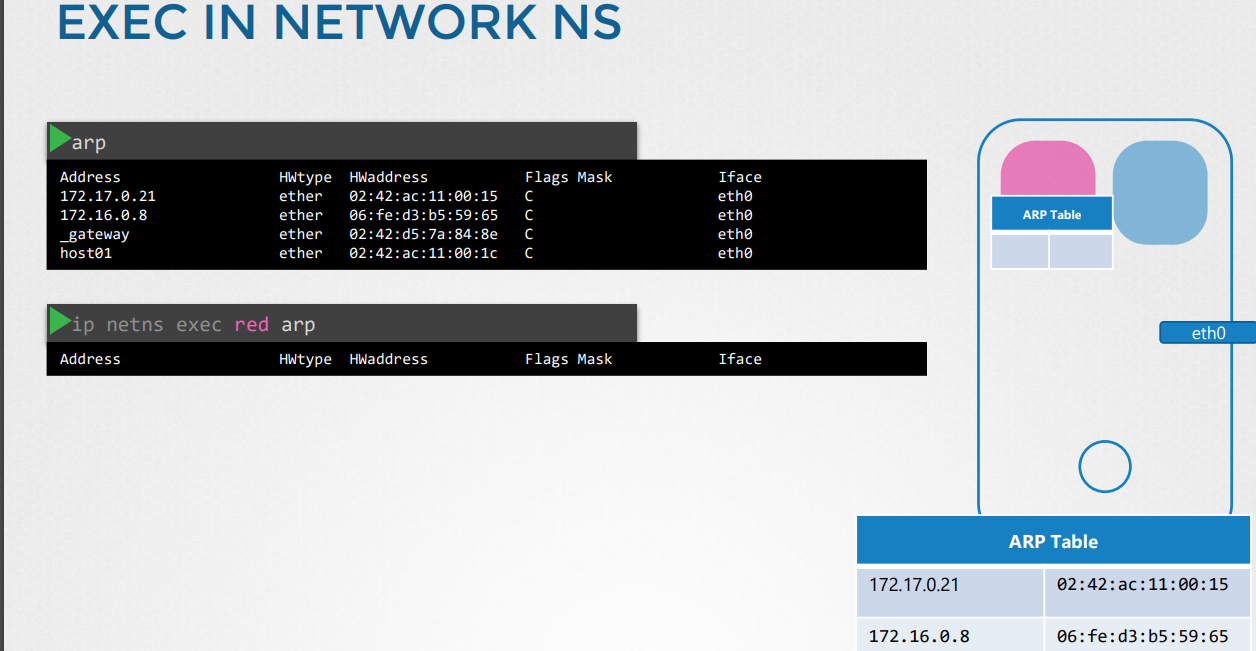

-네트워크 네임스페이스 red 안에서는 호스트의 eth0 인터페이스를 확인할 수 없음. ARP, Route에 대해서도 마찬가지임.
[네트워크 네임스페이스 간 통신 설정 순서]
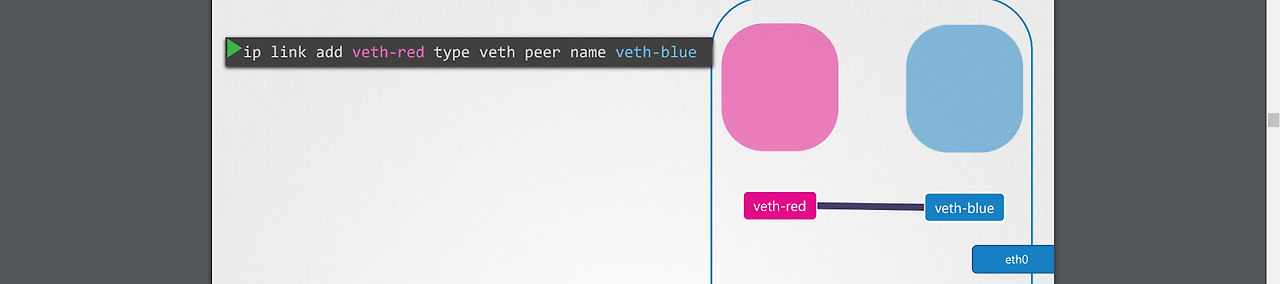
1.위 명령어로, 가상 인터페이스 페어가 되는 veth red, blue를 생성한다.

2.위 명령어로, 각 veth는 각각의 네트워크 네임스페이스에 할당한다.

3.각각의 veth에 가상 ip를 할당한다.
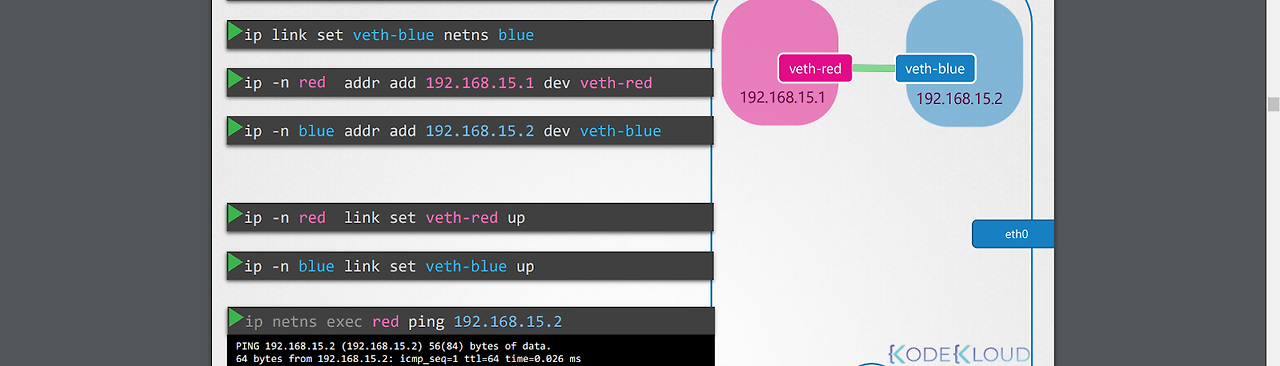
4.위 명령어로, veth를 활성화 시킨다.

5.각 red, blue 네트워크 네임스페이스 간 통신이 가능해졌고, 각각의 arp 테이블이 생성되었으며, 이는 host에서는 확인이 불가능.
*만약 두 개 이상의 네임스페이스가 존재할 경우에는?
[여러 네임스페이스 간 통신 설정 방법]

0.하나의 가상 네트워크를 만들기 위해 가상 스위치를 생성해야 한다. 가상 스위치는 위처럼 Linux Bridge 등의 여러 방식이 존재한다. 이때 생성하는 가상 스위치는 호스트 입장에서는 하나의 인터페이스로 볼 수 있으며, 네임스페이스 입장에서는 하나의 가상 스위치로 볼 수 있다.

1.bridge 타입의 가상 스위치를 생성한 후, down 상태인 v-net-0를 활성화시켜 해당 스위치를 사용할 수 있게 만든다.
-ip link add v-net-0 type bridge
-ip link set dev v-net-0 up

2.일단 네임스페이스-스위치용 인터페이스 pair를 생성한다.
-ip link add veth-red type veth peer name veth-red-br
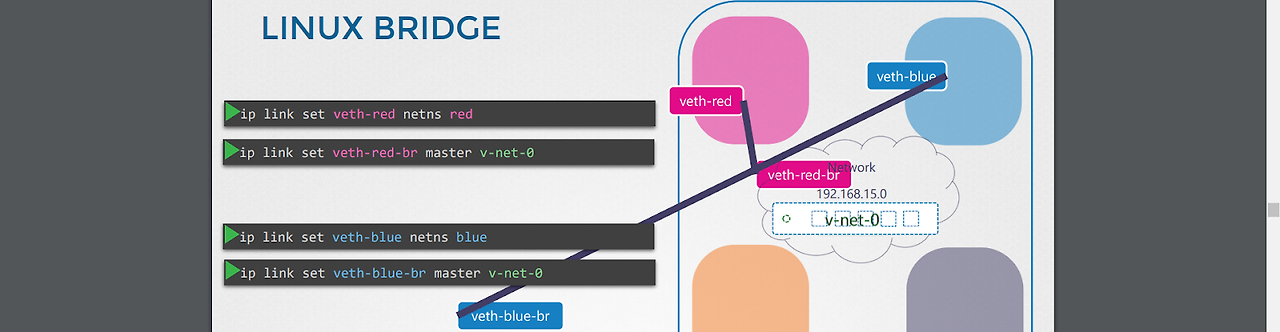
3.인터페이스 pair를 각각 네임스페이스, 브리지 스위치에 할당한다.
-ip link set veth-red netns red
-ip link set veth-red-br master v-net-0
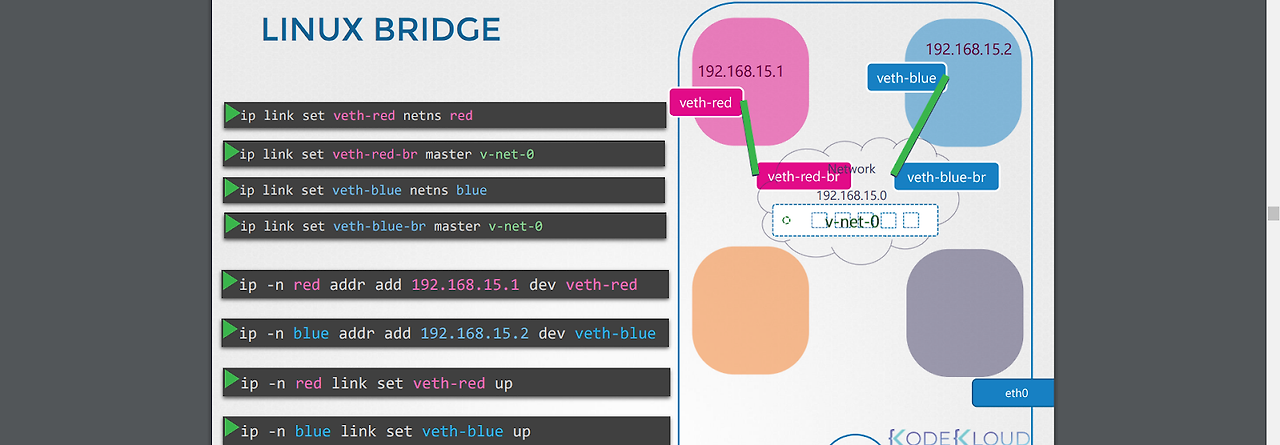
4.인터페이스에 ip를 할당하고 통신이 되도록 인터페이스를 활성화 시킨다.
-ip -n red addr add 192.168.15.1 dev veth-red
-ip -n red link set veth-red up
*호스트에서 네임스페이스에 접근하려면 어떻게 해야 할까?
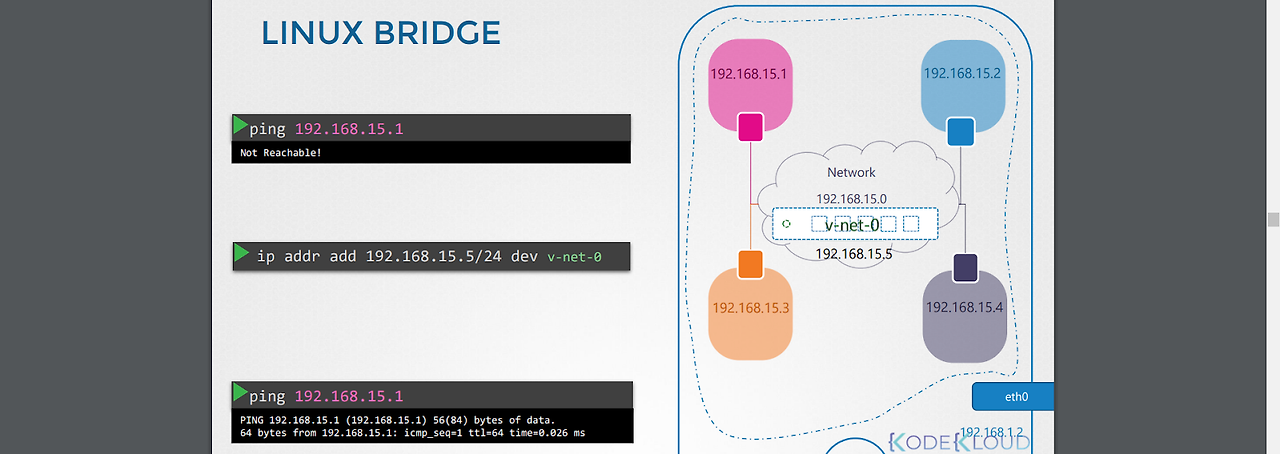
0.호스트는 v-net-0와 분리된 상태이므로 먼저 연결해줘야 한다. 가상 스위치는 사실 호스트의 인터페이스이기도 하기 때문에 이 인터페이스에 ip를 할당해줌으로써 호스트와 v-net-0와 연결이 가능해진다.
-ip addr add 192.168.15.5/24 dev v-net-0
*호스트 내 네임스페이스에서 LAN을 통해 다른 호스트에 어떻게 접근할 수 있을까?

1.네임스페이스에서 호스트를 gateway로서 route 테이블을 만든 후, ping을 보내면 가긴하는데 응답이 돌아오지는 않는다. 그 이유는, 외부에서는 ping을 보낸 blue 네임스페이스를 알지 못하기 때문이다.
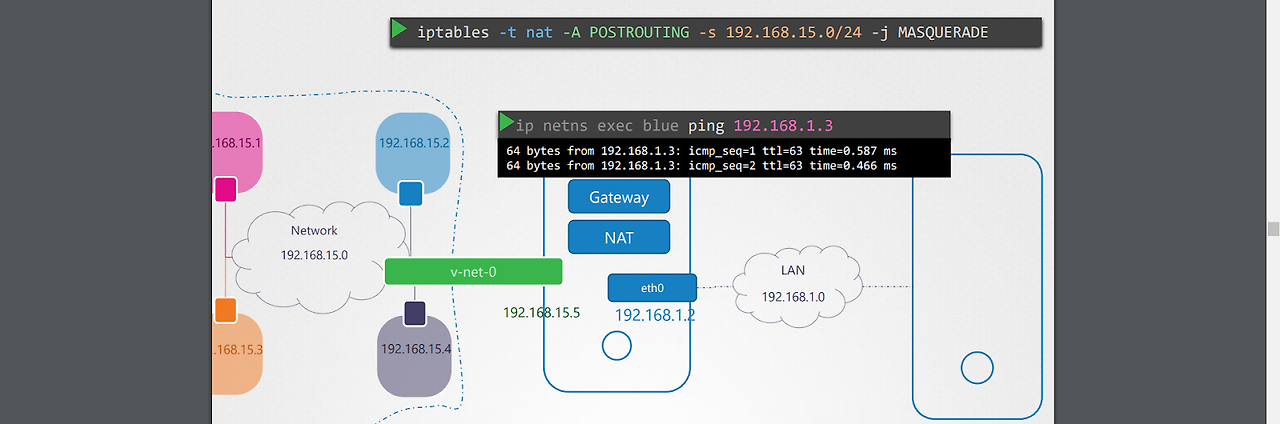
2.NAT 규칙을 생성하여, blue 네임스페이스에서 나간 패킷이 공인 호스트 ip 주소를 가지게끔하여, 외부에서 응답이 돌아올 때 제대로 호스트를 통해 blue 네임스페이스까지 돌아올 수 있도록 한다.
-iptables -t nat -A POSTROUTING -s 192.168.15.0/24 -j MASQUERADE
*LAN에 연결된 인터넷망으로 들어가려면 어떻게 해야 할까?

-라우팅 테이블 내 목적지 항목 값을 인터넷망으로 지정해줘야 한다. 그래야 LAN을 통해서 인터넷망으로 접근이 가능한 것 같다.
*외부 호스트에서 로컬 호스트에 접근하려면?
방법은 아래와 같이 두 가지가 있다.
1.외부호스트 내 라우트 설정 추가.
2.포트포워딩 설정으로 로컬호스트 내 특정포트로 인입되는 트래픽을 설정한 목적지 IP:PORT로 리다이렉팅.
-iptables -t nat -A PREROUTING --dport 80 --to-destination 192.168.15.2:80 -j DNAT
5. Prerequisite - Docker Networking

-네트워크를 지정해주지 않으면 nginx는 실행되지 않는다.
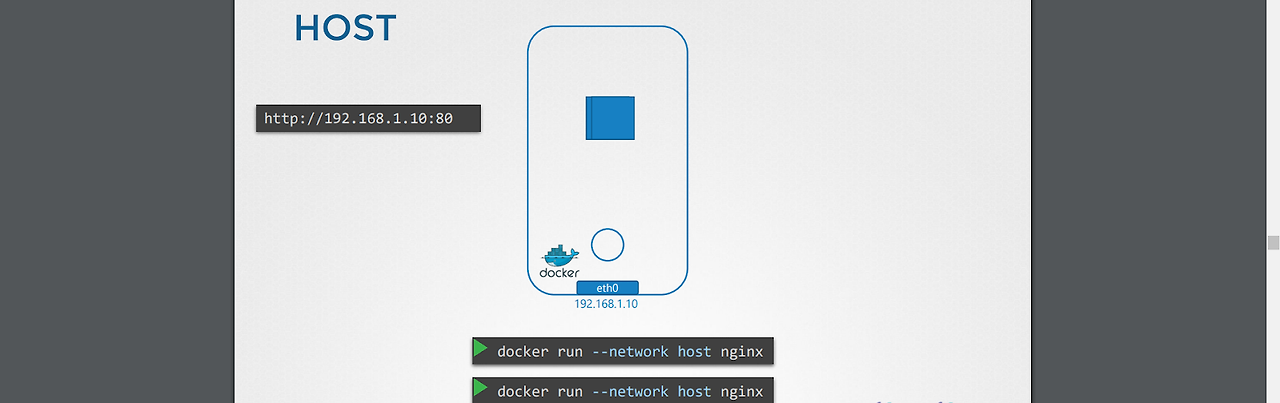
-네트워크를 host로 지정하면, 하나의 포트에 대해 하나의 웹 서버 프로세스가 실행된다.

-bridge 네트워크를 생성 후 내부에 컨테이너 생성.
[도커 기반 네트워크 생성 과정]

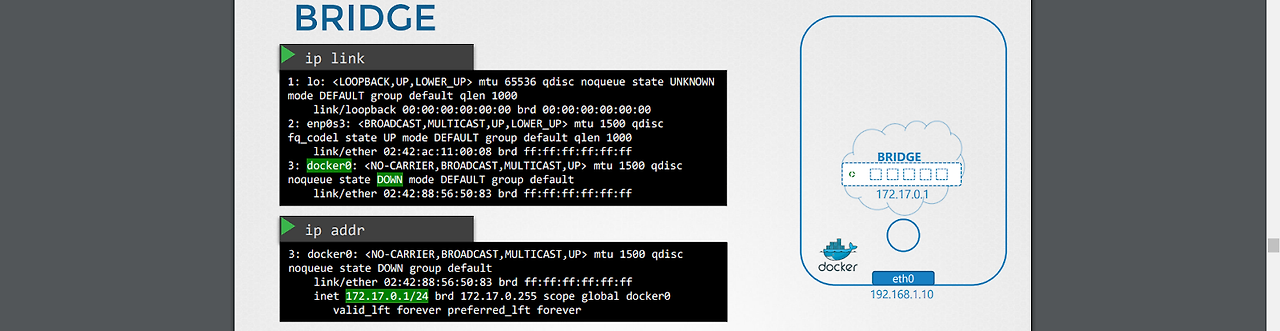
1.도커 실행 시 bridge 네트워크가 생성된다.
-이때 docker 명령어 시 조회되는 bridge는 ip link 시 조회되는 docker0와 같은 것이다.
브리지 네트워크는 호스트 입장에서는 인터페이스, 컨테이너 입장에서는 스위치인 셈이다.
-처음엔 캡처처럼 비활성화 되어 있음.

2.컨테이너 실행 시 해당 컨테이너를 포함할 네임스페이스가 자동으로 생성된다.
*도커는 어떻게 컨테이너, 네임스페이스를 브리지 네트워크에 포함시킬 수 있는 걸까?
-일단 컨테이너와 네트워크 네임스페이스는 같은 것으로 본다.
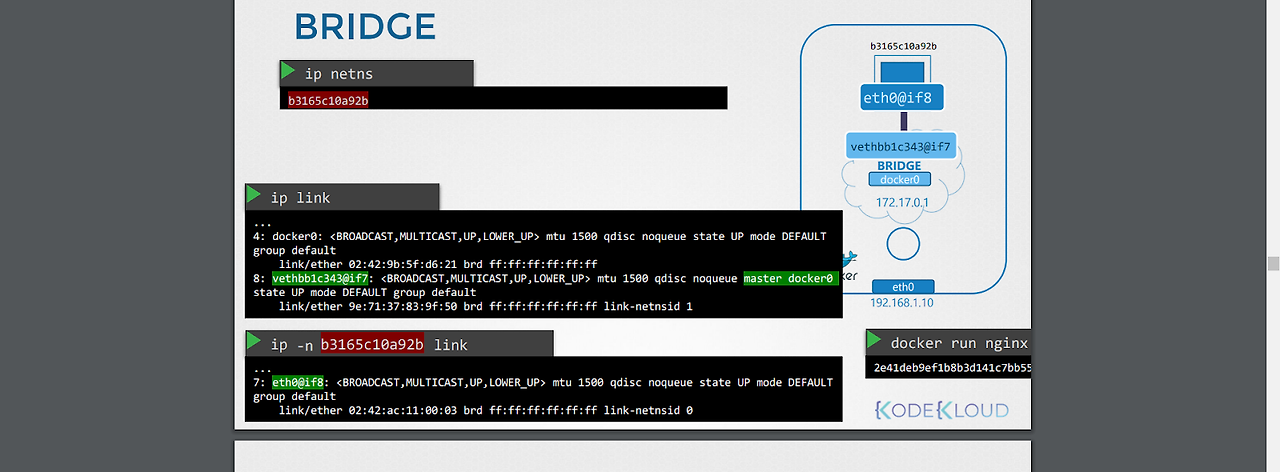
-docker run nginx 으로 만들어진 컨테이너에 대해 아래 명령어로 확인 시 컨테이너와 docker0에 각각 인터페이스가 붙어있는 걸 확인할 수 있다.
- ip link
- ip -n b31~ link

-컨테이너는 ip addr를 통해 ip를 갖는 걸 확인할 수 있다.
[도커가 컨테이너를 브리지 네트워크에 포함시키는 과정]
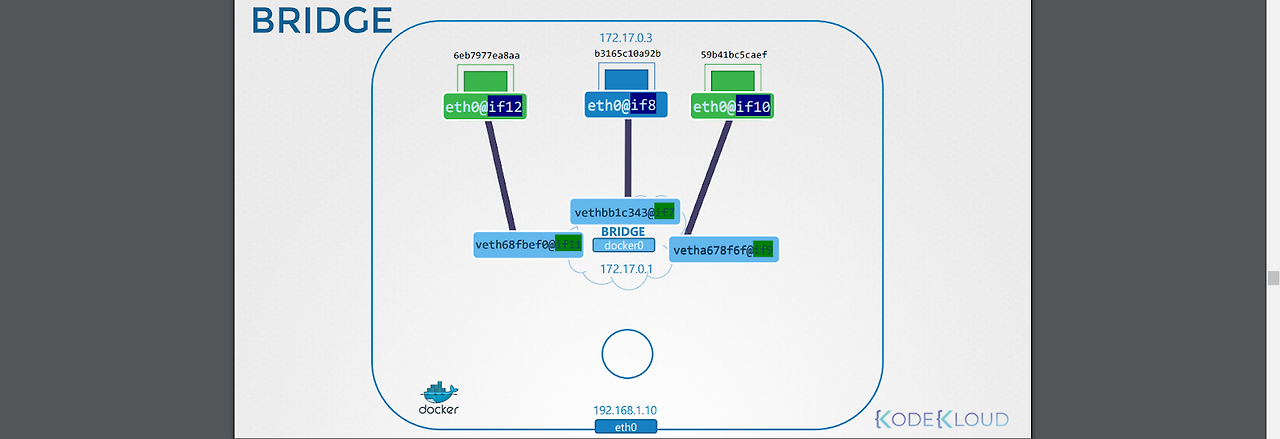
1.컨테이너 생성
2.컨테이너를 포함하는 네임스페이스 생성
3.인터페이스 쌍 생성
4.각 인터페이스를 컨테이너, 네임스페이스에 붙임
-인터페이스 쌍은 이름 끝에 붙는 숫자(연속된 숫자임)를 통해 구별된다.

-외부 호스트에서 본 호스트 내 컨테이너에 접근하려면 포트 포워딩을 통해 접근할 수 있다. 이때 아래 명령어로 포트포워딩된 컨테이너를 생성할 수 있다.
-docker run -p 8080:80 nginx
*도커는 어떻게 포트포워딩할 수 있는 걸까?

-NAT rule을 적용해서 본 호스트의 특정 포트로 들어오는 트래픽을 특정 컨테이너의 포트로 인입될 수 있게 한다. 즉 아래 명령어를 수행 시 내부적으로 NAT rule이 생성되어 적용되는 것 같다.
-docker run -p 8080:80 nginx
전체 NAT rule을 확인 명령어를 통해 해당 컨테이너의 포트포워딩 상태를 확인할 수 있다.
- iptables -nvL -t nat
6. Prerequisite - CNI
[CNI 배경]

-여러 컨테이너 런타임은 네트워크 네임스페이스를 생성 후에 각자만의 방식으로, 브리지 네트워크 생성 이후의 컨테이너 간 통신이 되도록 하는 전 과정을 비슷하게 수행한다
*각 런타임들이 동일하게 수행하는 작업을 공통된 코드로 통일하는 게 좋지 않을까?

-하나의 통일된 코드를 여러 런타임에서 사용하려면 아래 로직들에 대해 단일 기준이 필요하다.
- 위 bridge 프로그램을 호출하는 방식
- 어떤 인자, 명령어를 지원해야 하는지
-CNI는 위와 같은 로직을 통일하기 위해 프로그램을 어떻게 개발해야 하는지 정의된 기준이다.
-이러한 프로그램은 여러 개가 존재하며 플러그인으로 불린다. 위 bridge 프로그램도 CNI를 위한 플러그인이다.

[CNI에는 컨테이너 런타임과 플러그인이 수행해야 하는 역할이 정의되어 있다]
-컨테이너 런타임)
-네트워크 네임스페이스를 생성해야 한다.
-컨테이너가 연결되어야 하는 네트워크를 식별해야 한다.
-컨테이너가 생성 또는 삭제될 때 플러그인을 호출해야 한다. 아마 다음 작업을 위해서인 듯하다.
-해당 컨테이너 런타임 환경에서 플러그인 설정을 어떻게 할지 JSON 포맷으로 명시해야 한다.
-플러그인)
-추가, 삭제, 체크에 대한 인자를 지원.
-컨테이너id, 네트워크 네임스페이스 인자 지원.
-파드의 ip 할당, 파드 간 통신을 위한 라우트 설정 등을 관리할 수 있어야 함.
-결과값이 특정 포맷으로 리턴되도록 함.
-위 기준을 고수하면 어떤 런타임이든 어떤 종류의 플러그인이든 사용하여 컨테이너 환경을 관리할 수 있다.

-CNI는 bridge, vlan 과 같은 기존 플러그인을 바탕으로 수립되었다.
-도커만이, CNI를 구현하지 못하며, 자신만의 기준을 가지고 있다.
-하지만 네트워크를 설정하지 않고 컨테이너를 생성 후, 플러그인을 강제로 호출하여 컨테이너 환경을 구축할 수는 있다.
-docker run --network=none nginx
-bridge add 2e34dcf34 /var/run/netns/2e34dcf34

-도커 엔진을 사용하는 K8S에서 위 방식과 비슷하게 CNI를 사용하여 컨테이너 환경을 구축한다.
7. Cluster Networking

-클러스터 환경에서 각 노드들은 오픈되어야 할 특정 포트들이 있다.

-멀티 마스터 환경에서는, 각 마스터노드에 있는 ETCD client가 서로 통신하기 위해 해당 포트를 오픈해야 한다.

[실습 중요 내용]
-클러스터 연결을 설정하는 네트워크 인터페이스를 찾기 위해서는, 해당 노드의 ip가 어떤 인스터페이스로 연결되어 있는지 확인하기 위해 ip addr 명령어 수행.
-ip addr show type bridge 명령어로, type이 bridge인 link를 확인할 수 있다.
-netstat -lnp | grep -i schedu 명령어를 통해 스케줄러의 포트 번호를 알 수 있다. 중요한 건 netstat으로 네트워크 관련 설정을 알 수 있다는 것과 netstat —help를 통해 원하는 조회를 하는 것이다.
-netstat -apl | grep -i etcd: a 옵션으로 connected된 소켓을 확인할 수 있음.
-etcd의 2379 포트는 마스터 내 모든 컴포넌트가 연결된 포트이기 때문이다. 2380은 멀티 마스터 환경에서 마스터 간 연결만을 가진다.
8. Pod Networking
-k8s에서는 파드 네트워킹에 대해 내장된 솔루션이 없으며 파드 통신에 대한 명확한 요구사항을 가진다.
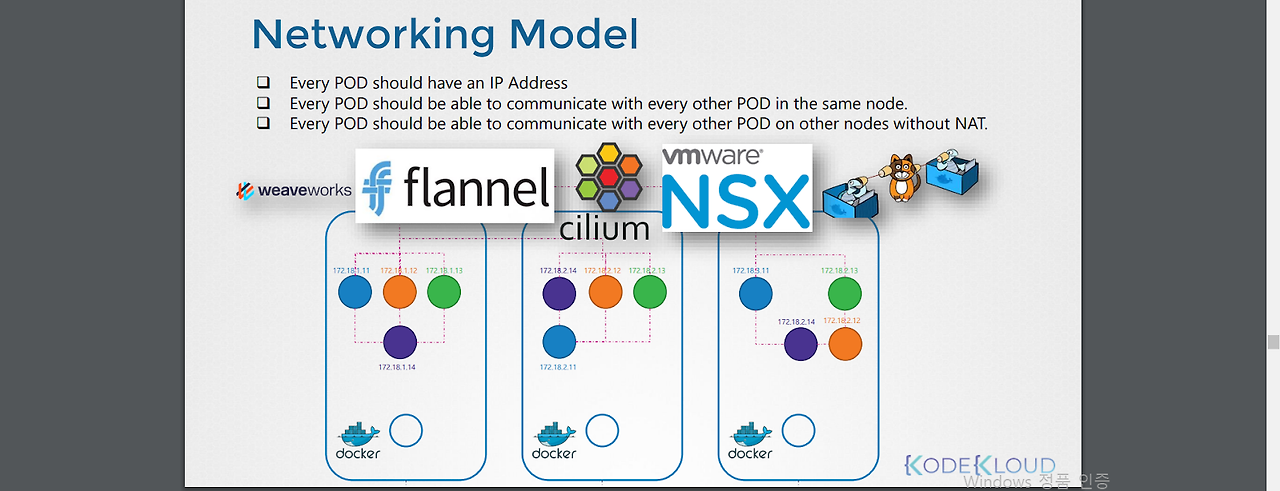
[파드 통신 요구사항]
1.모든 pod는 ip 주소를 가진다.
2.모든 pod는 노드에 상관없이 전 클러스터 내 pod들과 NAT 없이 통신이 가능하다.
[파드 간 통신 과정]
1.컨테이너가 만들어지면 이를 포함하는 네트워크 네임스페이스가 생성된다.
2.네트워크 네임스페이스를 붙일 브리지 네트워크를 add하고 up시켜 활성화한다.
-ip link set dev v-net-0 up
3.브리지 네트워크에 주소를 할당한다.
-ip addr add 10.244.1.1/24 dev v-net-0
4.파드와 브리지 네트워크를 아래 명령어들을 통해 연결한다.
# Create veth pair
-ip link add ……
# Attach veth pair
-ip link set ……
-ip link set ……
# Assign IP Address
-ip -n addr add ……
-ip -n route add ……
# Bring Up Interface
-ip -n link set ……
*위 단계에서는 일단 한 노드 내 파드 간 통신이 가능하게 되었다. 다른 노드 간 파드 통신이 되려면 어떻게 할까?
-각 노드에서 router 테이블을 만들어서 다른 노드의 파드와 통신한다.
*그런데 이러한 설정들을 많아 복잡해진다면 더 쉬운 방법은 없을까?

-더 좋은 방법은, 위처럼 하나의 라우터에서 각 노드 간 통신이 되도록, 이 라우터 서버를 기본 게이트웨이로 지정하면 관리가 용이하다.
-이렇게 되면 결국 각 노드에 생성한 브리지 네트워크는 하나의 큰 단일 네트워크처럼 동작하게 되는 것이다.
*하지만 파드가 많이 생성되는 환경에서는 파드와 브리지 네트워크를 연결하는 명령어를 포함한 스크립트의 작업량이 자체가 많아진다. 어떻게 이를 자동화 할 수 있을까? -> CNI를 통해 자동화되도록 작업하면 된다.

[CNI를 통한 파드 네트워킹 자동화 과정]
0.CNI는 k8s에게 컨테이너를 생성하자마자 스크립트를 호출하는 방법, 기준에 맞는 스크립트 명세 방법(add, delete..)을 지정해준다.
1.컨테이너런타임이 컨테이너를 실행한다.
2.런타임 실행 시, 명령줄 인자로 전달받은 cni 설정 경로를 바라보고 스크립트 경로를 확인한다.
3.스크립트를 실행하여 실행된 파드의 네트워킹을 설정한다.
9. CNI in kubernetes
k8s가 CNI를 통해 어떻게 구성되는지 알아보자.

-cni는 아래와 같이 런타임이 해야 할 역할을 정읜한다.
-컨테이너와 네임스페이스를 생성한다.
-컨테이너를 붙일 네트워크를 식별한다.
-올바른 cni를 호출하여 컨테이너를 네트워크에 붙인다.
-네트워크 구성 정보를 json 파일로 갖는다
*containerd가 특정 cni를 사용하기 위해서 어떤 구성이 필요할까? -> kubelet 실행 명령어에 해당 정보가 포함되어 있음.
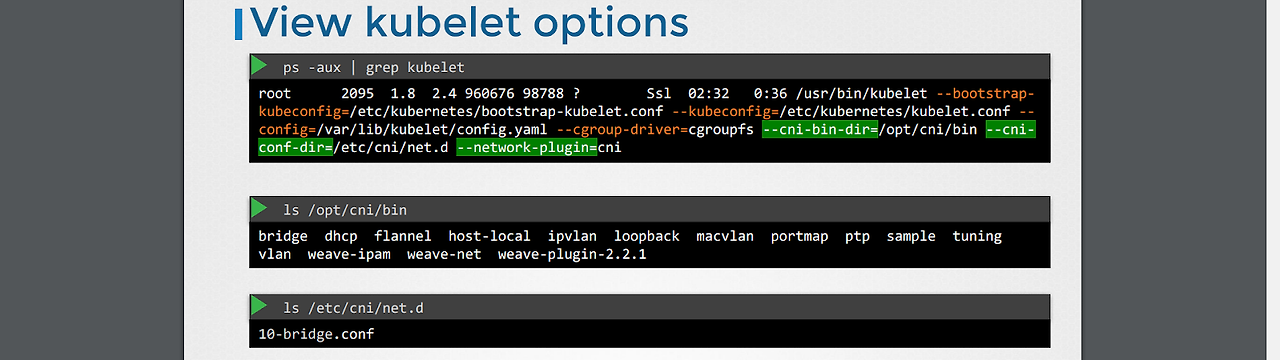
-cni 실행 파일의 위치는 /opt/cni/bin.
-어떤 cni를 어떻게 사용해야 할지에 대해 /etc/cni/net.d 에 위치한 플러그인 설정 파일들을 통해 확인한다.(여러 파일들이 있으면 알파벳 순서로 정한다?)
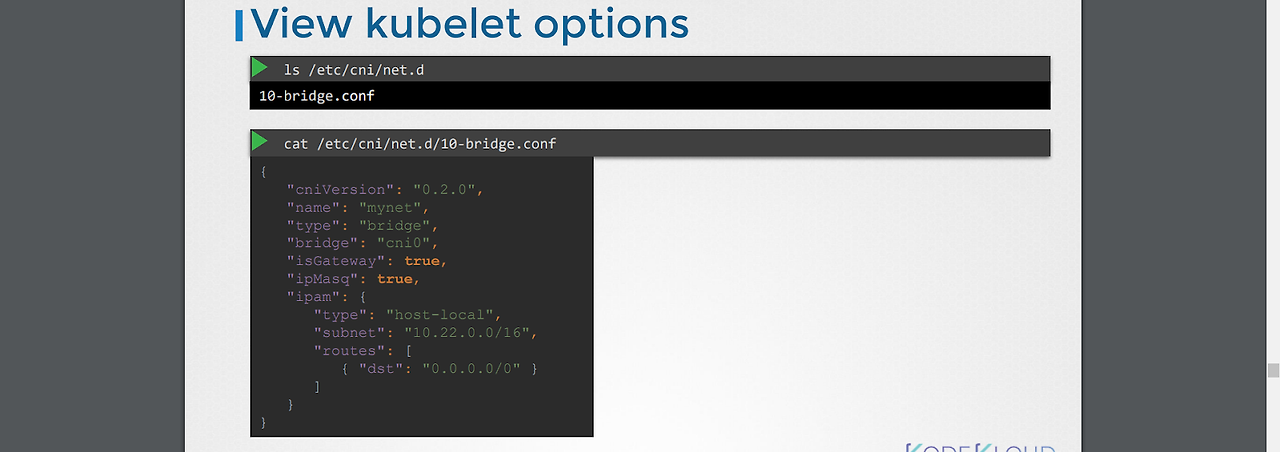
-cni 설정파일에서는 네트워크 이름, 타입, 기본 게이트웨이 설정 여부, 서브넷 등의 설정들이 정의되어 있다.
-참고로 IPAM은 IP 주소 매니저 정도로 해석하면 된다.
10. CNI weave
CNI가 어떻게 동작하는지 좀 더 알아보자.
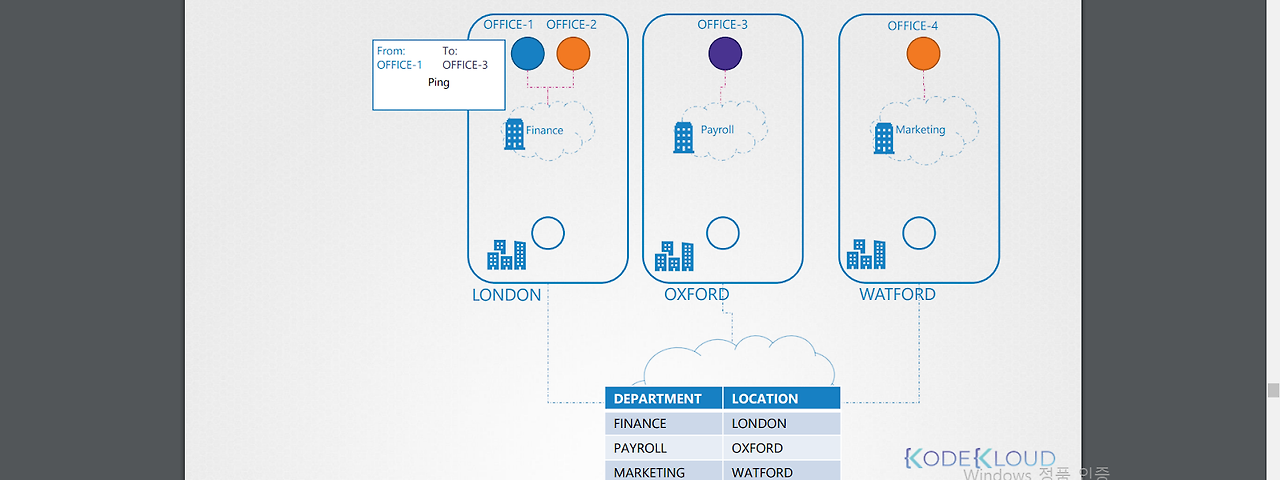
*라우터 서버에서 매핑정보를 보고 트래픽을 전달하게 되는데, 만약 노드, 파드 수가 많아지면 라우터 서버에 저장된 매핑 개체 수가 너무 많아져서 다른 방식이 필요하다. 이때 트래픽 전달에 최적화된 택배회사(weave)이 트래픽 전달을 전담하게 된다.
[weave를 사용한 트래픽 이동 과정]
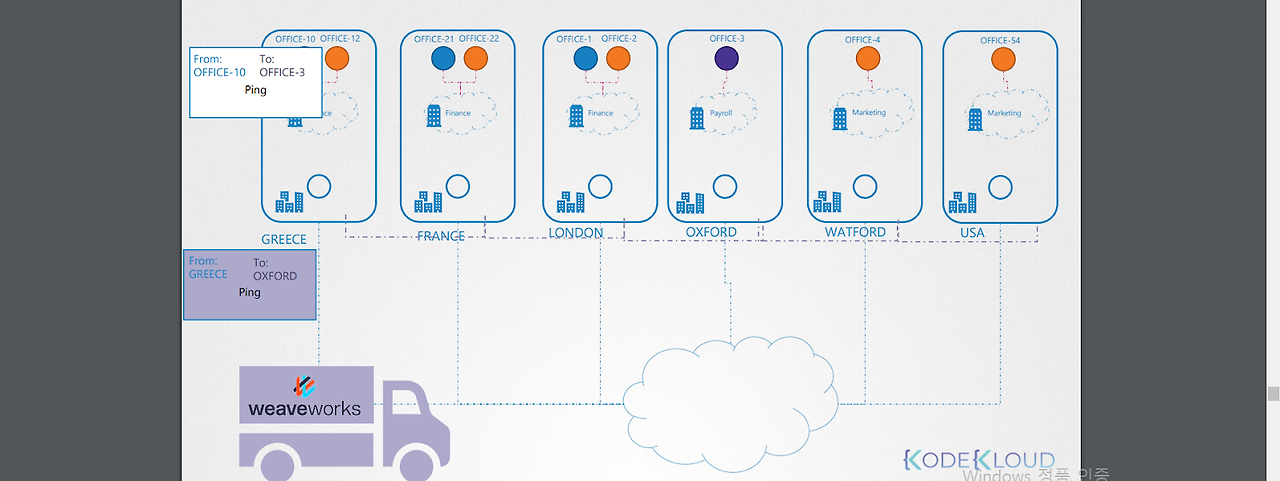
1.weave가 설치되면 각 노드에 agent를 두고, 각 노드 agent는 서로 통신하며 각자 노드에 있는 노드, 파드, 네트워크 정보를 알고 있다(저장하고 있다).
2.그래서 트래픽을 전달할 때 기존처럼 라우터 테이블을 통해 확인하지 않고, 출발지 노드에 있는 agent에서 목적지 정보를 우선 확인한다.
3.노드 수준의 패킷으로 감싸서 목적지 노드의 agent 에게 전달한다.
4.agent는 내부 패킷 정보를 확인해 목적지 파드에 트래픽을 전달한다.
*참고 사항
-각 노드에 있는 weave 서비스는 서로 통신한다.
-weave 역시 ip를 가진다.
-weave는 해당 노드 내 네트워크, 파드 정보를 저장하고 있다.
-파드는 weave 브리지 네트워크, docker 브리지 네트워크 두 개에 동시 할당 될 수 있다.
-weave는 파드가 보낸 요청이 weave agent에 가도록 하는 것을 보장한다?
*weave는 어떻게 배포할까?

1)service, deamon으로 수동으로 배포될 수 있다.
2)k8s가 셋팅되어 있다면 pod로 배포 가능.
-kubectl apply 명령어로 배포 가능.
-deamonset으로 배포된다.

3)kubeadm으로 weave 플러그인을 설치할 경우, 파드로 배포되는 걸 볼 수 있다
11. IP Address Management - Weave
노드 내 브리지 네트워크와 파드가 서브넷, ip를 어떻게 할당받는지에 대해 알아보자
*ip 할당 정보가 어디에 저장되고 무엇이 ip 할당 시 중복을 방지할 수 있을까?
1.간단한 방법으로, 각 호스트마다 ip 관리 목록을 파일로 저장하고, cni 호출 스크립트 내부에는 이를 체크하는 함수를 두는 것이다.

2.DHCP, host-local 방식으로 ip를 관리하는 플러그인을 두어서 해결할 수도 있다.

3./etc/cni/net.d/net-script.conf 설정에 사용할 플러그인 유형과 서브넷, 라우터를 지정해주고 cni 스크립트에서 이를 참조해서 원하는 방식으로 ip를 관리할 수 있다.
*weave에서 서브넷을 어떤 방식으로 할당하는가?

-할당받는 네트워크 대역에 대해 각 노드별로 동등하게 서브넷을 나누고, 각 노드에서 생성되는 파드는 해당 서브넷에 포함되는 주소를 가진다.
12. Service Networking
-pod는 노드에 호스트되는 반면, service는 클러스터에 걸쳐 호스트 된다.
-클러스터 내에서만 접근 가능한 서비스 유형을 clusterIP라고 한다.
-nodeport 서비스 유형은 모든 노드의 포트에서 해당 서비스에 접근해서 각 노드 파드에 접근이 가능하다.
-service는 특정 노드에 속하는 게 아닌 클러스터 전체 개념이다.
*service가 어떻게 ip를 할당받을까?
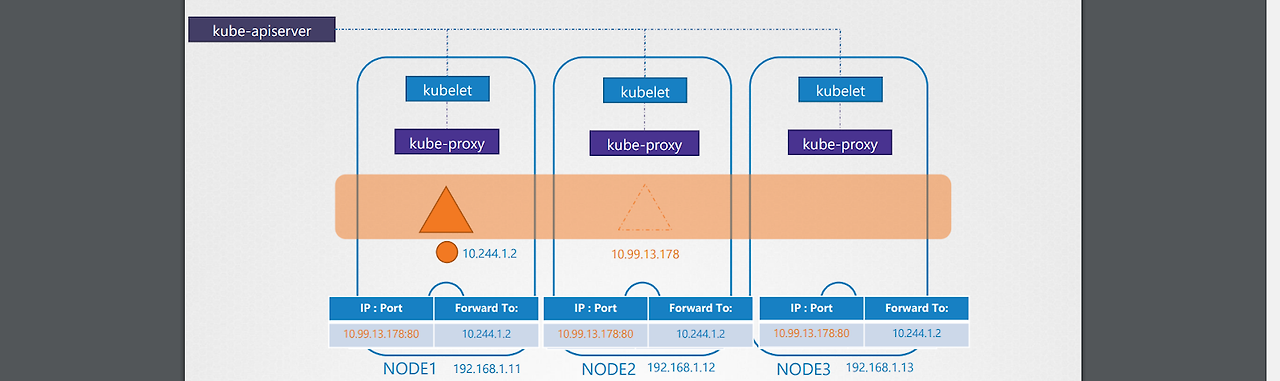
[할당받는 순서 과정]
1.정의된 범위에서 service 객체가 ip 주소를 할당받는다.
2.각 노드에 존재하는 kube-proxy 컴포넌트가 해당 ip에 대한 포트포워딩 규칙을 만든다.
*위와 같은 규칙은 어떻게 만들까?
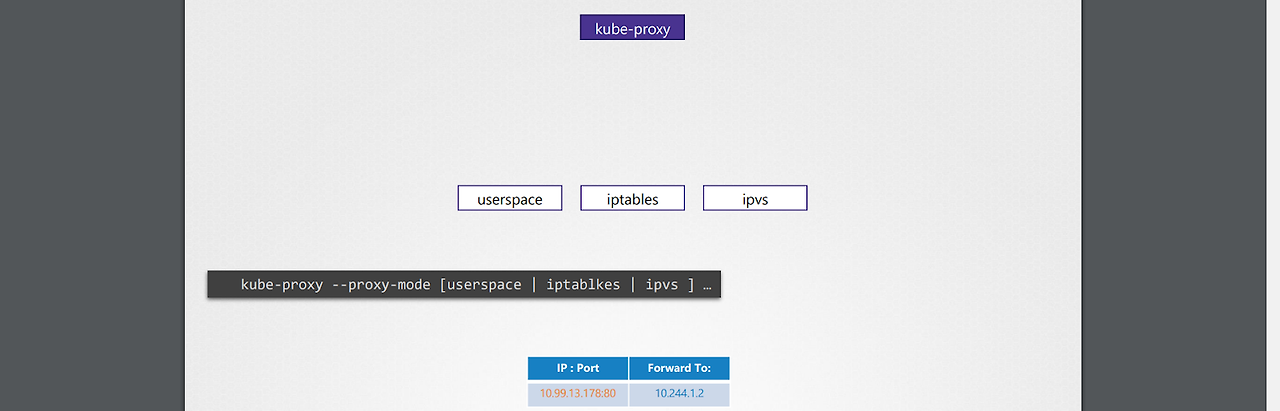
-기본값으로 iptable을 통해 규칙을 만든다.

-pod와 service의 할당 ip 범위는 서로 겹치지 않게 설정되어 있어서 중복되지 않는다.

-iptable을 통해 확인 가능.
-이러한 생성 정보는 kube-proxy log를 통해 확인할 수 있다.
[실습 중요 내용]
-파드의 ip 할당 범위는 cni 파드의 log를 통해 확인할 수 있다.
-service ip 할당 범위는 api-server yaml 파일에서 확인할 수 있다.
13. DNS in kubernetes
*k8s 클러스터 내부에서 dns가 어떻게 구성될까?
-k8s는 기본 탑재된 dns 서버를 배포함.

-service를 생성하면 dns 서버에 해당 hostname과 ip에 대한 매핑정보가 추가됨.

-매핑정보에서 hostname의 full name은 [hostname].[namespace].[type].[root] 정보로 매핑되게 된다.
*디폴트로 탑재되는 이 CoreDNS를 어떻게 구현할까?

-내부에서 동작하는 coreDNS는 일반적인 DNS와 비슷하게 동작한다.
1.각 파드에서는 /etc/resolv.conf 파일에 dns 서버 매핑 정보를 설정한다.
2.DNS 서버에 각 파드들에 대한 매핑정보가 있다.
-CoreDNS는 k8s에서 파드로 배포된다.

-coreDNS 파드 내 CoreDNS 실행파일이 실행되고 /etc/coredns/Corefile에 관련 내용이 정의되어 있다.