0. INDEX
- 스파크 Cache(캐시)에 대해 알아보기
- Repartition과 Coalesce에 대해 알아보기
- SQL Hint에 대해 알아보기
- 자료 카운트를 세는 Accumulator에 대해 알아보기
- Speculative Execution에 대해 알아보기
- Job Scheduling에 대해 알아보기
1. 스파크 Cache(캐시)에 대해 알아보기
cache는 spark 연산 시 추후 같은 데이터에 대해 재연산을 반복하지 않도록 데이터를 메모리에 저장하는 것을 말한다.
cache된 데이터는 데이터프레임이 각 워커노드에 파티션 단위로 분산되어 존재하듯 파티션 단위로 캐시공간에 로드되며 executor 내부, task 바깥에 존재한다. 이때 데이터가 executor의 storage 메모리에 들어가기 충분하지 않으면 disk 공간이 추가로 사용될 수 있다.

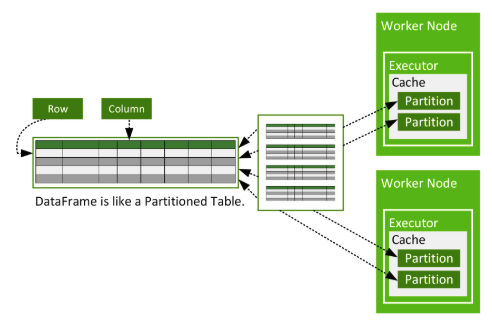
cache를 사용하는 데에는 두 가지 방법(cache(), persist())이 있으며, 캐시를 더 이상 사용하고 싶지 않을 때 unpersist()를 사용하면 된다.
1.cache()
cache() 메서드는 transformation이기 때문에 action이 나오기 전까지는 캐시가 수행되지 않는다.
아래 코드 1번처럼 캐시한 데이터를 변수에 저장하지 않고 캐시를 사용한 경우, 캐시한 논리적 계획과 똑같은 계획이 이후에 사용될 경우에만 캐시공간에서 데이터를 검색하여 엑세스할 수 있다.
코드 2번처럼 캐시한 데이터프레임을 변수에 저장한 경우에는 언제든지 해당 변수를 통해 캐시한 데이터에 접근할 수 있다.
#1. cache를 데이터프레임으로 저장하지 않는 경우
df.select ( "SNo" , "id" , "track_name" ).filter(col( "SNo" ) > 100 ).cache()
df.select ( "SNo" , "id" , "track_name" ).filter(col( "SNo" ) > 100 ).count() #test1
df.select ( "SNo" , "id" , "track_name" ).filter(col( "SNo" ) > 10 ).count() #test2
#2. cache를 데이터프레임으로 저장하는 경우
df_cached=df.select ( "SNo" , "id" , "track_name" ).filter(col( "SNo" ) > 100 ).cache()
df_cached.select ( "SNo" , "id" , "track_name" ).filter(col( "SNo" ) > 100 ).count() #test3
df_cached.select ( "SNo" , "id" , "track_name" ).filter(col( "SNo" ) > 10 ).count() #test4
참고로 위처럼 동작하는 이유는, spark 실행 계획 중 논리 실행 계획 단계에서 Optimizer보다 Cache Manager가 더 먼저 동작하기 때문이다. 즉 Cache 이후에 최적화를 한다. 따라서 캐싱 시, 위 코드의 2번처럼 cache()를 호출한 결과 DataFrame을 변수에 저장해 사용하는 것이 더 안전하고 좋다.
2.persist()
cache()에는 없는StorageLevel 옵션을 아래 중에서 지정할 수 있다.(참고로 cache()는 persist()의 memory_and_disk storage level과 같음)
Storage Level Space used CPU time In memory On-disk Serialized Recompute some partitions
----------------------------------------------------------------------------------------------------
MEMORY_ONLY High Low Y N N Y
MEMORY_ONLY_SER Low High Y N Y Y
MEMORY_AND_DISK High Medium Some Some Some N
MEMORY_AND_DISK_SER Low High Some Some Y N
DISK_ONLY Low High N Y Y N- MEMORY_ONLY: 역직렬화된 객체로 JVM 메모리에 저장하는 방식으로, 데이터를 직렬화 했을 때보다 당연히 더 많은 메모리가 필요하다. 사용 가능한 메모리가 충분하지 않으면 일부 파티션의 DataFrame이 저장되지 않으며 필요할 때 다시 계산해야 하므로 MEMORY_AND_DISK 수준보다 느리다.
- MEMORY_ONLY_SER: 객체를 직렬화된 상태로 저장하는 방식으로, 연산 시 역직렬화 과정이 추가되므로 MEMORY_ONLY보다 적은 메모리를 사용하지만 연산이 더 소모된다.
- MEMORY_AND_DISK: DataFrame 연산 시 기본 동작되는 storage level로, DataFrame은 역직렬화된 객체로 JVM 메모리에 저장되며, 메모리 사용량이 큰 경우 일부를 디스크에 저장하고 필요할 때 디스크에서 데이터를 읽는다.
- MEMORY_AND_DISK_SER: MEMORY_AND_DISK 방식과 메모리와 디스크에서 DataFrame 객체를 직렬화한다는 점에서 다르다.
- DISK_ONLY: DataFrame은 디스크에만 저장되기 때문에 느리고 CPU 연산량이 크다.
무조건 캐시를 해두는 것은 좋지 않다. 큰 규모의 데이터 셋에서는 캐시 비용이 높아지므로 오히려 재연산을 하는 것이 나을 때도 있다. 추가로, 더 이상 쓰이지 않는 RDD라고 해서 자동으로 캐시가 해제되지는 않는다. unpersist 함수를 호출하거나 메모리 공간의 부족으로 축출(evict)되기 전까지는 메모리에 남아있게 된다. spark는 executor가 메모리 부족을 겪을 때 뺄 파티션을 결정하기 위해 LRU(Least Recently Used) caching 방식을 사용하여 쓰인지 가장 오래된 데이터를 뺀다.
2. Repartition과 Coalesce에 대해 알아보기
spark를 통해 분산 데이터 처리를 할 때 중요한 것 중 하나가 바로 파티션이 골고루 분배되도록 하는 것이다. 그렇지 않으면 OOM가 발생하는 등 분산 처리의 효과를 누리지 못하기 때문이다. 또한 파티션이 골고루 분산되어 있어도, 작업 도중 데이터 수가 줄어들어 파티션 수를 줄이는 것이 효과적일 경우도 있다. 이처럼 여러 이유로 파티션 수의 조정이 필요할 때 spark에서는 repartition(), coalesce() API을 통해 파티션 수를 조정할 수 있다. 두 API의 가장 큰 차이점은 셔플링 유무이다.
1-1. repartition()
repartition은 보통 파티션 수를 늘려(줄이는 것도 당연히 가능) 데이터 처리의 병렬성을 높이기 위해 사용한다. hash based로 파티셔닝을 하기 때문에 파티셔닝이 전 노드에 균일하게 배치되지 않을 수 있다. 또한 wide transformation으로 각 워커노드에 분산되어 존재하는 모든 파티션에 대해 셔플링이 일어나는, 전역적인 재배치 작업으로 비용이 많이 든다. 메모리 이슈가 나거나, skewed 상황일 때 repartition 작업을 수행해 데이터를 재배치하면 개선될 수 있다.
반면, partition수를 줄이려고 할 때는 전역적 재배치가 발생하는 repartition보다 각 워커노드에 존재하는 파티션들을 병합하는 방식의 coalesce를 사용하는 것이 더 좋다.
1-2. repartiotionByRange()
해시값이 아닌 데이터 값을 기반으로 파티셔닝한다.
2. coalesce()
보통 작업 도중 데이터 수가 줄어 성능 향상을 위해 파티션 수를 줄이고자 사용한다. 각 워커노드에 존재하는 파티션들을 병합하는 지역적인 방식으로 파티션을 합치하기 때문에 셔플링 비용이 repartition()보다 덜(거의X) 발생하게 된다. 하지만 그만큼 skew 데이터 혹은 OOM이 발생할 가능성이 있다. 단, 파티션 재설정 수를 급격하게 낮추면 병렬성이 낮아지기 때문에 이 점을 고려해 사용해야 한다.

#1-1.파티션 수를 2개가 되도록 리파티셔닝 작업 수행
df_repartitioned = df.repartition(2)
#1-2.파티션 수가 2개가 되도록 + age 컬럼값을 기준으로 파티셔닝을 진행한다.
df_repartitioned = df.repartitionByRange(2, "Age")
#2. 기존의 파티션 수가 2개 이상일 때, 2개로 줄인다.
df_coalesced = df.coalesce(2)
셔플링이 일어나는 repartition()이 coalesce()보다 성능이 무조건 나쁜 것은 아니다. 셔플링을 하게 되면 executor는 쌓아두었던 메모리를 한번 refresh 하기 때문에 executor의 메모리 사용량이 많은 시점에서는 repartition()을 통해 이를 한번 해소해주는 것이 더 좋을 수 있다.
3. SQL Hint에 대해 알아보기
[why?]
hint는 쿼리 상에서 조인이나 파티셔닝 등에 대해 사용자가 원하는 방식대로 쿼리를 수행하도록 지정해주는 문법이다. 사실 spark에서는 SQL Optimizer를 통해 join을 어떤 방식으로 수행할지 자동으로 최적화해준다.
그렇다면 이걸 사용하는 경우가 있다는 것인데 왜 사용하는 것일까? 예를 들어, 특정 작업에 필요한 적합한 파티션 수를 미리 알고 있다면 힌트를 사용하여 파티션 수를 최초에 지정하여 작업 효율성을 높일 수 있을 것이다. 즉 데이터에 대한 정보를 미리 알고 있을 수록 이러한 힌트 사용은 큰 힘을 발휘할 것 같다.
[사용 예시] : select 이후 hint를 준다.
#1. repartition으로 파티션닝하도록 hint 구성한 코드
df.createOrReplaceTempView("table")
spark.sql("SELECT /*+ REPARTITION(3, c) */ * FROM table")
#2. 작은 테이블 table2를 브로드캐스트하여 조인하도록 sql hint 구성한 코드
df1.createOrReplaceTempView("table1")
df2.createOrReplaceTempView("table2")
spark.sql("SELECT /*+ BROADCAST(table2) */ * FROM table1 JOIN table2 ON table1.Name = table2.Name")4. 자료 카운트를 세는 Accumulator에 대해 알아보기
[왜 accumulator를 사용해야 할까?]
예를 들어 아래와 같이 데이터프레임에서 특정 조건을 충족하는 데이터 레코드의 수를 계산하는 예제가 있다고 하자.
상식적으로 #1.과 같이 record_count=0 으로 변수를 생성해도 문제가 없을 것 같지만, spark의 데이터 분산 처리 특성 상 #1의 방식은 의도한대로 동작하지 않는다. 그 이유를 알기 위해 해당 코드의 동작방식을 살펴보자.
- #1처럼 변수를 사용했을 때 코드 동작 방식)
- spark 작업이 시작되면 드라이버 프로세스는 record_count와 이를 참조하는 *closure 인 count_records_with_age_above_threshold 함수를 직렬화하여 각 executor에게 보낸다.
- 각 executor는 본인에게 전달된 파티션 데이터에 대해서 record_count를 증가시킨다. 이때 각 executor가 record_count를 각각 가지고 있으며 드라이버 프로세스에 역전파 되지 않기 때문에 결과적으로 의도한 record_count 변수는 드라이버 프로세스에서 작업이 끝나게 되도 0인 상태로 남는다.
의도한 값을 얻기 위해서는 #2의 방식인 accumulator를 사용해야 한다. accumulator는 spark에서 제공하는 공유변수로,
각 task에서 해당 공유변수에 접근할 수 있도록 애초에 드라이버 프로세스에서 각 워커노드에 record_count 변수를 전파한다. 그리고 각 task에서는 해당 변수에 값을 더하거나 뻬는 것만이 가능하며(읽을 수는 없다) 이에 대한 변화가 드라이버 프로세스에 역전파된다. 해당 변수는 드라이버 프로세스에서만 해당 공유변수에 접근이 가능하다.
from pyspark.sql import SparkSession
# SparkSession 생성
spark = SparkSession.builder \
.appName("Accumulator Example") \
.getOrCreate()
# ====================================
#1. 단순 변수로 생성
record_count = 0
#2. 가산기 생성
record_count = spark.sparkContext.accumulator(0)
# ====================================
# 예시용 데이터 생성
data = [("John", 25), ("Anna", 30), ("Mike", 35), ("Emily", 28)]
rdd = spark.sparkContext.parallelize(data)
# 특정 조건을 충족하는 데이터 레코드의 수 계산
def count_records_with_age_above_threshold(record):
global record_count
if record[1] > 30:
record_count += 1
# 맵 함수를 사용하여 각 데이터 레코드에 대해 변수값을 증가시킴
rdd.foreach(count_records_with_age_above_threshold)
# 변수의 값 출력
print("Number of records with age above threshold:", record_count.value)
# SparkSession 종료
spark.stop()
[Accumulator의 특징]
- accumulator는 결합 및 가환 연산만을 지원한다. 즉 연산 순서를 바꾸어도 결과가 같아야 한다. 아무래도 분산 컴퓨팅에서는 데이터의 작업 순서가 보장되지 않기 때문이다.
- action연산을 수행할 때에만 accumulator 값이 갱신된다.
[사용 시 주의사항]
- transformation과 함께 사용하게 되면 값이 중복 계산될 수 있기 때문에 action 연산에서만 사용하는 것이 좋다. spark작업은 다양한 이유로 실패할 수 있기 때문에 accumulator 연산이 포함된 특정 stage, task가 실패 후 재작업을 수행하는 상황에서는 accumulator는 중복 계산이 되므로 의도한 결과를 얻지 못한다.
5. Speculative Execution에 대해 알아보기
spark의 분산 처리 특성 상 특정 노드의 하드웨어적 결함으로 인해 해당 노드에 배치된 task가 오래걸려 전체 작업이 지연될 수 있다. 이러한 상황에서 spark에서는 작업 속도를 향상시키기 위해 해당 task와 똑같은 쌍둥이 task를 다른 노드에 lunch해서 병렬 수행시키는 것이 speculative execution이다.(이후 두 task 중 하나가 끝나게 되면 남아있는 task는 실행시킬 필요가 없기 때문에 삭제된다)
그럼 어떻게 speculative execution을 할 수 있는 것일까? spark는 작업을 완료하는 데 필요한 시간을 모니터링하고 있기 때문에 이 시간을 통해 특정 task가 다른 task보다 오래걸린다면 speculative execution을 실행한다.
[관련 config]
--spark.speculation true # 기본값은 false
--spark.speculation.interval 500ms
--spark.speculation.multiplier 1.5
--spark.speculation.quantile 0.9- spark.speculation.enabled: 이를 true로 설정하면 speculative execution이 활성화되며 기본값은 false임.
- spark.speculation.interval: speculative execution이 시작되기 전에 작업이 지연되는 시간을 지정. 기본값은 100ms.
- spark.speculation.multiplier: speculative execution이 시작되는 조건을 지정하는 것으로, 예상 시간을 초과한 작업이 평균 작업 시간의 이 배수를 초과할 때 speculative execution이 시작됨. 기본값은 1.5.
- spark.speculation.quantile: speculative execution이 시작되는 작업의 예상 시간을 결정하는 것으로, 기본값은 0.75. 예를 들어 task들의 75%가 끝났다면 활성화함.
[결론]
Speculative Execution는 Data Skew, 적은 메모리 할당으로 인한 실행 지연을 faulty worker node로 오인하는 문제가 발생할 수 있기 때문에 남용해서 사용하면 안된다. 하드웨어적 결함이 없더라도 데이터적 특성 및 리소스 할당 값의 문제로 overhead를 동반하기 때문에 대다수의 경우 선호되지 않는다고 한다. 따라서 대체로 사용할 필요가 없지 않을까 싶다. 지연되는 task에 대해 쌍둥이로 실행하는 컨셉이기 때문에 비용이 많이 들어서 fine tuning을 위한 다양한 옵션이 제공되는데, 특별한 문제가 있지 않는 한 거의 안쓸 것 같다.
6. Job Scheduling에 대해 알아보기
spark에서는 application이 제출되었을 때 내부 job들이 어떤 기준으로 수행순서가 정해지는지, 나아가 application 자체가 여러 개가 수행될 때는 이들 간의 수행 순서가 어떻게 정해지는지에 대해 알아보도록 하자.
[scheduling across application] - dynamic resource allocation
spark application이 다수가 존재할 때 리소스 관리를 어떻게 할 것인지에 대한 스케줄링이다. 기본적인 방식은 먼저 들어온 application1에 대한 작업이 모두 끝날 때까지는 이후에 들어온 application2에 리소스를 전혀 할당하지 않는다. 반면 동적인 방식은 application1의 작업 중 하나의 stage가 끝났을 때 release된 리소스(cluster에 반환되는) 있다면 그걸 application2에서 사용할 수 있게 한다. 또한 추후 stage에서 리소스가 더 필요하게 된다면 cluster에 리소스를 추가 요청해서 사용하게 된다.
# 동적 할당 활성화
export SPARK_DYNAMIC_ALLOCATION_ENABLED=true
# 최소 Executor 수 설정
export SPARK_DYNAMIC_ALLOCATION_MIN_EXECUTORS=2
# Executor 유휴 시간 설정
export SPARK_DYNAMIC_ALLOCATION_EXECUTOR_IDLE_TIMEOUT=60s
# 셔플 트래킹 활성화
export SPARK_DYNAMIC_ALLOCATION_SHUFFLE_TRACKING_ENABLED=true- spark.dynamicAllocation.enabled: 기본값은 false이며, true로 설정하면 동적 할당이 활성화됨.
- spark.dynamicAllocation.minExecutors: 클러스터에서 유지할 최소 Executor 수를 지정하며 동적 할당이 활성화된 경우, 이 값은 Executor의 최소 갯수임.
- spark.dynamicAllocation.executorIdleTimeout: Executor가 유휴 상태로 대기하는 시간을 지정하며 이 시간이 경과하면 유휴 Executor가 제거됨.
- spark.dynamicAllocation.shuffleTracking.enabled: 이 값을 true로 설정하면 셔플의 크기와 지속 시간을 추적하여 리소스 할당을 최적화할 수 있음.
[scheduling within application] - spark job scheduler
spark application 하나에 대해 내부 job들에 대한 스케줄링이다. 기본적으로는 하나의 application 내 각 job들이 수행될 때 순서대로 수행되는 FIFO 방식을 사용한다. 하지만 각 job들이 순서대로 수행되는 것이 아니라, 아래 설정을 통해 쓰레드들을 통해 병렬적으로 수행될 수 있도록 설정할 수 있다.(spark 0.8부터 도입)
spark job은 스케줄링 pool 안에서 동작하는데 이 pool의 job 실행방식을 "fair"로 설정해서 해당 pool을 스케줄러로 사용할 때 여러 job들이 병렬적으로 돌아가게 하는 것이다. 아래와 같은 xml 파일을 참조하여 spark에서 원하는 방식으로 스케줄링을 적용할 수 있다.
- 스케줄러가 참조하는 스케줄링 pool이 정의하는 xml 파일
<allocations>
<pool name="production">
<schedulingMode>FIFO</schedulingMode>
<weight>1</weight>
<minShare>0</minShare>
<weightMode>fixed</weightMode>
</pool>
<pool name="development">
<schedulingMode>FAIR</schedulingMode>
<weight>2</weight>
<minShare>0</minShare>
<weightMode>fixed</weightMode>
</pool>
</allocations>- name: 스케줄링 풀의 이름을 지정.
- schedulingMode: 스케줄링 모드를 지정하는 값으로, FIFO 또는 FAIR을 사용할 수 있음.
- weight: 스케줄링 풀의 가중치를 지정하는 값으로, 가중치가 높을수록 해당 풀에 할당되는 리소스가 많아짐.
- minShare: 최소 리소스 할당량을 지정.
- weightMode: 가중치 모드를 지정하는 값으로, 예로 고정된(fixed) 가중치를 사용할 수 있음.
- 실행 예시
spark-submit \
--master yarn \
--deploy-mode cluster \
--conf spark.scheduler.mode=FAIR \
--conf spark.scheduler.allocation.file=/path/to/scheduling-pool.xml \
--class com.example.MyApp \
my-app.jar- --conf spark.scheduler.mode=FAIR: Spark의 스케줄러 모드를 지정하는 옵션으로 이 경우에는 FAIR 스케줄링 모드를 사용함.
- --conf spark.scheduler.allocation.file=/path/to/scheduling-pool.xml: 스케줄러 할당 파일의 경로를 지정하는 옵션으로 이 파일에는 스케줄링 pool의 정의가 포함되어 있음.
추가적으로 두 스케줄링 방식의 차이점 중 하나는 Spark Job Scheduler의 리소스 공유 단위가 CPU cores인 반면, Dynamic Resource Allocation의 리소스 공유 단위는 Executor이다.
[결론]
업무 중에 spark를 사용할 때 특정 작업의 규모가 커서 리소스를 다 잡아먹을 경우에는 이후 실행된 다른 application들은 계속 대기상태에 남게 되는 것을 보았다. 이런 경우 scheduling across application 관련 설정을 튜닝하여 중간에 해소되는 리소스를 사용할 수 있게 해주는 실험을 해보면 좋겠다.
참고 자료)
- 1. spark cache)
- storage level
https://sparkbyexamples.com/spark/spark-persistence-storage-levels/
Spark Persistence Storage Levels
All different persistence (persist() method) storage level Spark/PySpark supports are available at org.apache.spark.storage.StorageLevel and
sparkbyexamples.com
- cache가 계획되는 단계
https://1ambda.blog/2021/12/25/practical-spark-cache-7/
- cache 모식도
https://velog.io/@rymyung/Apache-Spark-Cache%EC%99%80-Persistence
Apache Spark - Cache와 Persistence
Cache와 파일 형식
velog.io
- LRU 캐싱
[Apache Spark] RDD 재사용을 위한 영속화(persist, cache, checkpoint)
스파크는 RDD 재사용을 위해 몇가지 옵션을 제공한다. (persistence, caching, checkpointing)
jaemunbro.medium.com
- 2. repartition과 coalesce
https://medium.com/@amitjoshi7/repartition-coalesce-in-apache-spark-76eb6203c316
Repartition & Coalesce in Apache Spark
In the world of distributed computing, challenges like data spill and data skew often loom large. Data spill occurs when the volume of…
medium.com
https://brocess.tistory.com/183
[ Spark ] 스파크 coalesce와 repartition
해당 내용은 '빅데이터 분석을 위한 스파크2 프로그래밍' 책의 내용을 정리한 것입니다. 실제로 실무에서 스파크로 작업된 결과를 hdfs에 남기기전에 coalesce명령어를 써서 저장되는 파일의 개수
brocess.tistory.com
- 4.Accumulator
https://proedu.co/spark/what-is-spark-accumulator-with-example/
What is Spark Accumulator with example - Proedu
Accumulators are shared variables provided by Spark that can be mutated by multiple tasks running in different executors.
proedu.co
https://devidea.tistory.com/67
[Spark] Accumulators
Spark 으로 ETL 작업을 처리하다가 처리한 데이터의 누적 양을 집계하고 싶었다. 예를 들면, Kafka의 데이터를 활용해 spark streamming 작업을 할 때, 각 단계(spark streaming은 짧은 간격의 배치)마다 처리
devidea.tistory.com
https://medium.com/@ishanbhawantha/all-about-apache-spark-accumulators-in-plain-english-5ba0d349ee9
All About Apache Spark Accumulators in Plain English
Introduction
medium.com
- speculative execution
https://yousry.medium.com/spark-speculative-execution-in-10-lines-of-code-3c6e4815875b
Spark speculative execution in 10 lines of code
Resiliency against random software or hardware glitches.
yousry.medium.com
- job scheduling
https://www.samsungsds.com/kr/insights/spark-cluster-job-server-2.html
클러스터 리소스 최적화를 위한 Spark 아키텍처 ② | 인사이트리포트 | 삼성SDS
클러스터 리소스 최적화에 대해 쉽게 설명한 글입니다. Spark Context관리를 바탕으로 Spark에서 제공하는 Fair Scheduler와 Dynamic Resource Allocation 기능을 사용하여 효율적으로 리소스를 관리하는 방법에
www.samsungsds.com
'Data Engineering > Spark' 카테고리의 다른 글
| Spark Section5 - Apache Spark Streaming, 실시간 데이터 처리 라이브러리 (0) | 2024.04.13 |
|---|---|
| Spark Section3 - Apache Spark 엔진 Deep Dive(1) (0) | 2024.03.31 |
| Spark Section2 - Apache Spark SQL과 Dataframe(데이터프레임) (0) | 2024.03.12 |
| Spark Section1 - Apache Spark RDD 특징 및 예제 (0) | 2024.03.12 |
| Spark Section0 - Apache Spark 소개 (0) | 2024.03.12 |



